

The highest possible predictive power of your models
How confident are you that your risk models show what you need to see? Would your regulator agree?
The impairment model will impact investment decisions and create additional challenges in your accounting, modelling and reporting functions
Written by Jaydeep Sengupta, Consultant.
As the IFRS9 regime has come into effect, financial institutions, have increasingly turned to external agencies or "Vendors" for model development. However, the utilization of these models is not exempt from distinct risks that necessitate tailored model risk management procedures. The primary objective of this discussion is to highlight the typical hazards that emerge from the use of vendor models, with a particular emphasis on the risks that are exclusive to IFRS9 usage. Like other models employed in the financial industry, vendor models are complex in each of the domains related to their conceptual soundness, including data, design, and outcomes. Nonetheless, evaluating these domains with the same degree of rigor for a vendor model, in contrast to an in-house model, can be particularly challenging due to the proprietary components that vendors may choose not to disclose to the model user. The employment of vendor models for IFRS9, however, intensifies the significance of these developmental aspects. In this post, we will elucidate on the pertinent factors that should be considered when addressing these risks and provide industry-standard & feasible mitigation strategies.
The utilization of vendor models for risk management in the financial services sector is a conventional approach, especially among lenders who lack their own model development methodologies. This section discusses the typical users of vendor models in the regulatory context of risk management.
Financial institutions (“FIs”) of significant size and complexity, falling within the scope of the Basel mandates, are typically equipped with in-house models capable of estimating expected losses. While such models may cover a shorter time horizon than that required for IFRS9, these institutions have already invested extensively in data, infrastructure, and expertise, enabling them to comply with these regulations while employing sophisticated and refined model risk management practices. Consequently, these institutions have the option to repurpose their existing IRB models for IFRS9 compliance, making necessary modifications as required. Given their substantial portfolio sizes and abundant data availability over an extended period, they also possess the flexibility to create new models tailored specifically for IFRS9 usage. Moreover, the well-established modelling practices within these larger FIs further facilitate the adoption of either approach.
Smaller FIs are often unable to develop in-house models for IFRS9 compliance due to a lack of adequate data over an extended time horizon, and a shortage of the necessary model development skills. Starting from scratch, while an option, has the potential for the cost of model development to outweigh the benefits of regulatory compliance. As such, the optimal choice for these institutions would be to explore a vendor solution.
Employing vendor models as a means of risk estimation represents the practice of outsourcing, however, it does not necessarily entail abandoning the responsibility of managing model risk. It is essential for the model user, specifically FIs in this context, to effectively manage the risks that arise from employing vendor models. It is of utmost importance to assess the potential risk that may arise from the unsuitability of the vendor model for the intended portfolio.
Using vendor models can pose significant risks due to their proprietary nature, particularly regarding transparency. Vendors often withhold specific components of the models from users, such as variable transformations and parameter estimates, resulting in varying degrees of non-transparency depending on the vendor. Another risk is the data used to develop vendor models, which is typically based on vast amounts of industry data that may not fully represent the user FI's portfolio characteristics. Vendor models also provide Personalization options, which may not be appropriate for the intended model use and can lead to inappropriate usage if not transparently communicated. These risks are applicable across business objectives but are particularly relevant to the usage of vendor models for IFRS9.
It is customary for a vendor model that has been developed for a specific objective to be repurposed for alternative uses. In this context, vendor models that were originally designed to function as credit scorecards have been enriched with supplementary components to extend their applicability for IFRS9 purposes. An example of this extension is the TTC to PIT converter component, which, as the name implies, transforms the through-the-cycle (TTC) probability of default estimations that have been derived from the credit scorecards into point-in-time (PIT) estimations that are required for IFRS9 purposes. Typically, vendors market a suite of such models as a product suite, which creates incremental risk. Therefore, users of vendor models for IFRS9 purposes must scrutinize each individual component both independently and in combination with other models that are included in the vendor solution suite.
FIs face unique risks when using vendor models, which can be broadly categorized into two types. The first type is the risk associated with the model's development, which includes evidence from the vendor and the intended portfolio of model use. The vendor bears the responsibility for developmental risks, while the institution-specific risks require the user to exercise due diligence. Implementing external vendor models in FIs also requires heightened levels of due diligence, and model users must establish contingency plans in case the vendor fails to provide services. Properly accounting for each of these individual risks is crucial to managing vendor model risk effectively. With respect to using vendor models for IFRS9, some atypical risks may arise, and specific risks may be magnified. These nuanced considerations, which are discussed subsequently and briefly represented in the figure below, form the foundation for effective management of vendor model risk when using it for IFRS9.
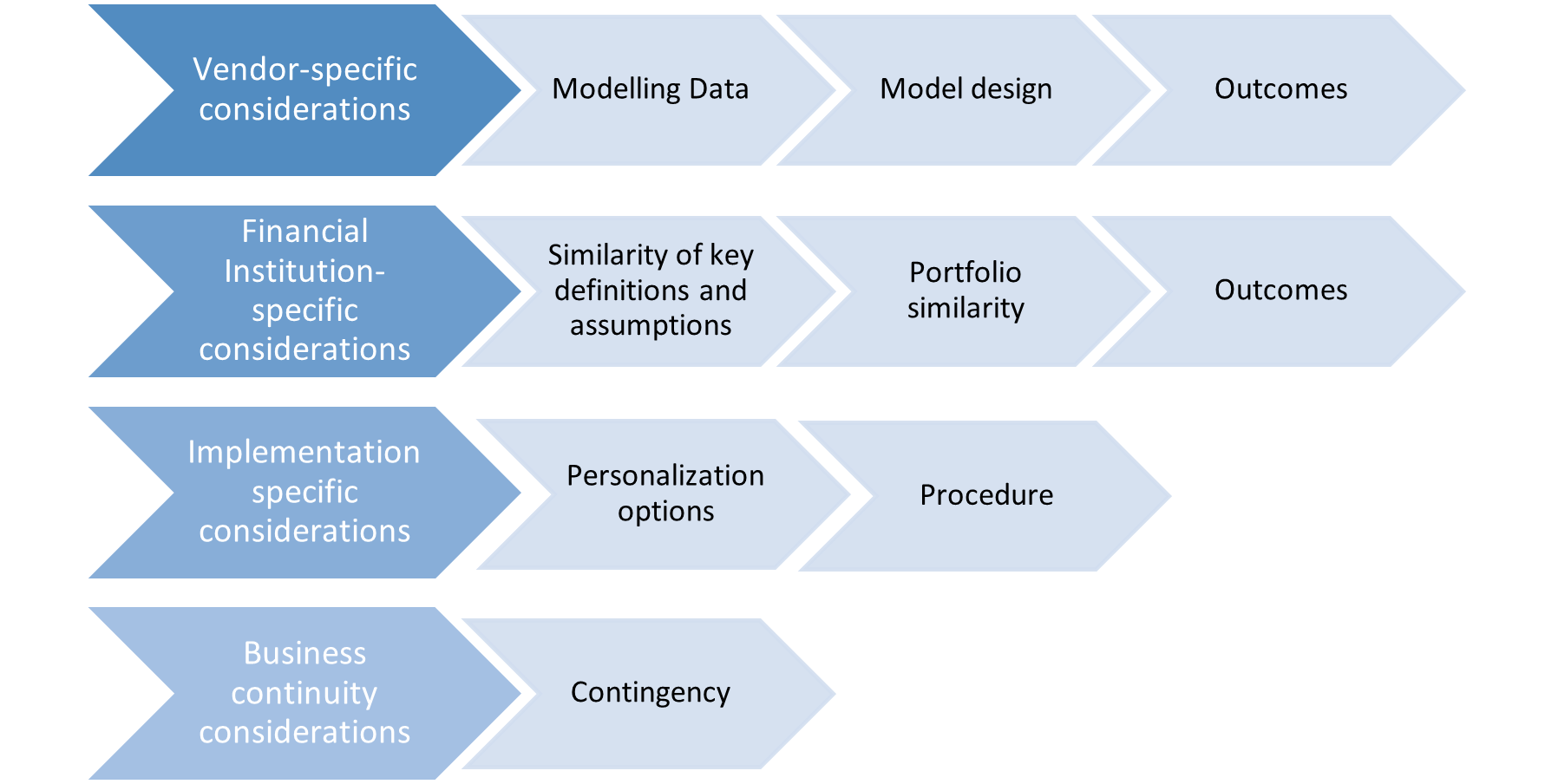
Vendors providing pre-made models either acquire data from external sources or gather and store it internally. In either scenario, those utilizing the model must assess the vendor's data management practices to ensure the reliability of the data used to create the model. To evaluate the quality of the development data, users of vendor models should focus on aspects such as the data timespan coverage, topographical coverage, and portfolio dimensional coverage. The evaluation should be tailored to the intended purpose and portfolio of use. This discussion will cover key data-related considerations regarding vendor model usage, particularly in the context of IFRS9.
Data timespan is essential for IFRS9, and the coverage of data from the 2008 recession is crucial for modelling sensitivity to changes in the macro-economy. If the model includes data from the 2008 recessionary period, users of vendor models for IFRS9 must ensure that the in-sample and out-of-sample data adequately represent the recessionary period. Diverse stress coverage is an issue with the typical approach of including data from the 2008 recessionary period, as it only considers a singular type of recession. This approach falls short of addressing the impact of recent events such as the COVID-19 pandemic on the macro-economy, making it necessary to include data from various types of recessions in model development, such as those resulting from the SARS or the H1N1 outbreaks.
Data recency is another crucial facet, as it is common for vendor models developed for Basel III to be repurposed for IFRS9 as such, it is likely that the model is not trained on recent industry data. Therefore, the model user must evaluate whether the vendor should recalibrate the model by incorporating recent data or assess the model's performance on the most recent out-of-time data. Product specifications are also relevant, as the term of the product being modelled should determine the timespan used for development. Mortgages, with typically longer terms, require data from a longer time span, than say HELOCS.
Regarding topographical coverage, vendor model users operating across multiple geographies must evaluate whether the development data includes portfolios from individual geographies. A granular evaluation of model sensitivity to the macro-economy at the state or metropolitan level is necessary for the applicability analysis of the model to respective portfolios of intended use. The granularity of model sensitivity to macroeconomic changes facilitates IFRS9 compliance, which requires macroeconomic factors to be considered in loss estimation.
The data used for developing vendor models should cover the portfolio of intended model use from multiple dimensions, such as the borrower's characteristics or the underlying collateral. As an example, for CRE loans, the most commonly used dimension is the property type of the collateral, wherein, hotels are typically considered to be riskier than offices. For C&I loans, the industry sector the borrower belongs is a dimension to be considered. A detailed inspection of portfolio dimensional coverage should accompany the usage of vendor models to ensure a high-level understanding of portfolio details along key dimensions. Subject matter expertise, such as defining an expert panel, and accepted industry practices should be applied to ensure appropriate definitions of these dimensions.
In addition to the IFRS9 related aspects of data preparation, the general steps to ensure data quality are also to be considered. Data treatment through imputing missing values, capping or flooring outliers, and other such manipulations form sound ground for the downstream development of a robust model. Lastly, transparent documentation of the data exclusions applied to the developmental data ensures that the model users apply the same set of exclusions in the data on which the model is intended to be used.
Assessing the design of a model involves reviewing its conceptual soundness and modelling aspects, such as segmentation, sampling, and estimation technique, in line with its intended use and the available portfolio. Evaluating the design of a vendor model, however, is typically more difficult due to the proprietary nature of the model and the vendor's potential reluctance to disclose certain design details. This section aims to outline key principles for evaluating the design of a vendor model in such situations of limited transparency. Additionally, it discusses critical design aspects for using vendor models in IFRS9 and highlights the personalization options unique to vendor models.
Conceptual soundness of design: The vendor may consider certain design aspects of model development as proprietary and may conceal them. The line between what constitutes proprietary information and what should be shared can be difficult to differentiate. Therefore, it is important for users of vendor models to use discretion to ensure that they can evaluate the conceptual soundness of the model without hindrance due to lack of design information. Users should demand additional model details beyond what the vendor provides in the model documentation, such as the final list of variables and related transformations, along with their corresponding descriptions. For models based on parametric approaches, vendors should provide details of variable statistical significance (p-values) and coefficient directionality. While vendors may provide high-level details of how the final set of variables was chosen, details of variable transformations and business rationale used to include or exclude variables may not always be available. To manage model risk effectively, users should expect increasing transparency from vendors as the complexity of the model design increases.
IFRS9 mandates generation of forward-looking lifetime estimates that require the interplay between portfolio characteristics and the macro-economy to be captured in the modelling scheme. The loan-level approach is welcomed across the industry by regulators alike. It therefore emerges as a key consideration regarding the design of a vendor models intended to be used for IFRS9.
IFRS9 mandates point-in-time (PIT) loss estimates over the forecast horizon. Much of the longstanding vendor models in the industry were initially developed to generate through-the-cycle (TTC) estimates of credit risk that require modifications to align with the intended usage for IFRS9. To this end, such models require to have inbuilt settings which allow for conversion of TTC estimates of credit risk to PIT ones. Another option that is commonly seen in the industry is for vendors to market a suite of models, one of which generates TTC estimates, and another converts the TTC estimates to PIT. While they align with the overall model scheme with the intended IFRS9 usage, such model suites have the potential to result in incremental model risk.
Personalization option: It is important to consider the level of customization required for the specific user and intended use of a vendor model. Vendor models are designed to be used by various lending institutions for different business purposes, which can lead to inappropriate model usage due to the inherent opaqueness of some model aspects. To mitigate this risk, vendors typically offer personalization options that allow users to adjust certain model settings to align with their portfolios and intended use. One such option is to calibrate the model outputs to historical portfolio performance. However, these personalization options also expose the model to customization risk as some model features may have default values that are not suitable for the intended use. Therefore, it is crucial for the model user to carefully assess the personalization features provided by the vendor and predefine appropriate values for each option.
The weightage of qualitative models is an additional calibration option for users of models. Although quantitative models are often deemed insufficient in capturing all the key drivers of credit risk for the intended portfolio, especially for vendor models developed on external data, qualitative models are frequently used to supplement them. Qualitative models can capture effects that quantitative models cannot, and therefore, combining both outputs using weightages is common practice, which is customizable by the model user based on their judgment. During times of stress, such as the recent COVID-19 pandemic, a greater reliance on qualitative models may be necessary to capture non-quantitative measures of risk that are not captured in the data. However, it is recommended that model users should aim to use analytical approaches wherever possible.
Regulations now require greater emphasis on evaluating outcomes from vendor models, since these models are created externally by modelling experts and may contain proprietary components. Despite this, model users must apply the same level of scrutiny, if not more, to outcomes from vendor models as they do for in-house models. Therefore, model users should ensure that appropriate testing results from the vendor are submitted. When analysing outcomes, several metrics should be used, each serving a different defined purpose. This is particularly important for smaller FIs that do not have well-developed MRM practices. Outcome testing should focus on the following key considerations that are relevant for vendor model usage, particularly in the context of IFRS9.
Actuals vs Forecasted for IFRS9: The appropriateness of the testing results is of magnified essence in instances when a vendor model is used for a business objective different from what it was originally developed for. Again, consider the example of a vendor model developed to serve as an origination scorecard. The validation scheme of such a model would likely involve evaluation of metrics such as Gini, KS, and plots such as the lift curve. These constitute standard validation practices prevalent in the industry for a scorecard. However, usage of this scorecard, with inbuilt modifications or with a supplemental model, for an intrinsically different objective such as loss forecasting warrants the validation mechanism to be altered accordingly. To elaborate, validation of models used for loss forecasting exercises, require a comparison of historical actuals with model predictions over calendar time. This ensures that the model outcomes are tested in alignment with the intended model implementation mechanism.
It is of prime importance for the model users to obtain a graphical representation of this comparison along with error metrics such MAPE, RMSE etc. from the back testing exercise. Model users should use these back testing results to identify systemic errors in model predictions. This facilitates estimation of the need for, and the extent of, compensating controls in downstream model usage. At this juncture, model users should also compare the expectations from predictions when the model is used for IRB against when it is used for IFRS9. Model users should work with the vendor to evaluate model outcomes in alignment with these conditions.
Snapshot-based back testing: Snapshot-based back testing is a crucial component of IFRS9 model validation, in addition to back testing model predictions with actuals over time. It is essential to test models using snapshot-based mechanisms during the validation process. The validation tests must incorporate the proposed methodology of model implementation. The marginally mitigated risks associated with a particular model can be identified by acceptable results from snapshot-based back tests. However, it is rare to see vendor models being tested based on this scheme. During the initial stages of information gathering, model users should ensure that the vendor submits snapshot-back testing results for snapshots belonging to different economic cycles. Ideally, snapshots from both the recessionary period and recent times should be included. Graphical representations of snapshot-based back testing results, supplemented by error metrics, can help identify the systemic tendency of models to produce inaccuracies for IFRS9 model usage and define compensating controls.
Sensitivity analysis: For IFRS9 usage, it is required for the vendors to subject the model to varying degrees of stress to the input macroeconomic factors and to evaluate the corresponding changes in the outputs. While it is typical for the stress applied to the macroeconomic factors to represent either sides of the economy, the recessionary stress results should be emphasized upon. Another essential consideration is that the impact of stressed inputs should be conducted at both the model-level (PD and LGD for example), and also at the overall-level (EL for example).
In the likely absence of design particulars of vendor models, there is a magnified importance of sensitivity analysis for managing model risk. As such, model users should improvise to obtain added perspective around model sensitivity. In addition to traditional methods of conducting sensitivity analysis, model users should require the vendor to obtain sensitivity analysis results at a more granular level. As an example, for models on CRE or C&I portfolios, the vendor should be expected to furnish model sensitivity at a property type or industry sector level respectively. This assists the model user to identify segments of the portfolio for which the model is not sensitive.
Evaluating model sensitivity to different macroeconomic scenarios is more important now than ever. With the recent COVID-19 pandemic, model predictions are being tested to the hilt. While this warrants models, in general, to be subjected to increased levels of stress, it becomes more important for vendor models. With diminishing regulatory trust on macroeconomic forecasts, model users should stress-test the models on forecasts based on extreme scenarios also, preferably in collaboration with the vendor. These efforts should be aimed at obtaining added comfort on the model predictions.
It is essential to establish robust monitoring schemes that involve ongoing assessment of model outcomes. The model user should monitor the model performance on internal data, while the vendor should transparently communicate the monitoring results on the latest industry data as it is collected. It is best practice to incorporate most of the tests from the model validation exercise conducted during development into the monitoring framework, as well as align with regulatory mandates. Additionally, the model user must ensure that the data used by the vendor to monitor the model outcomes remains relevant to the internal portfolio. Any discrepancies between the monitoring data and the data used to develop the model must be disclosed by the vendor to the model user. In this case, the model user should work collaboratively with the vendor to address such discrepancies and align the underlying monitoring data with the internal portfolio.
The FIs are vulnerable to risks stemming not only from the model's conceptual elements, but also from its improper application. Even if the vendor model is fundamentally sound, using it outside its intended setting could increase the risk associated with the model. Thus, it is necessary for the model user to implement controls.
An in-house model development is typically limited by the prevailing policies and definitions within the organization, which causes a significant risk when using a vendor model. The vendor may impose assumptions or definitions on the model development process, such as their definition of default, which could differ from the user's definition or not as per New Definition of Default. To ensure alignment of key definitions during model usage, the user must evaluate the vendor model design for any discrepancies and resolve them. For instance, if the vendor's default definition is 180 days past due (DPD) while the user's is 90 DPD, the user may need to request a recalibration of the vendor model to align with internal accounting practices. From an IFRS9 perspective, a key component is the definition of significant increase in credit risk (SICR). The vendor model is bound to be used based on this SICR classification assumed by the institution. How the design of the vendor model aligns with this assumption is a key consideration to be accounted for by the model user.
The effective use of vendor models requires adequate representation of the intended portfolio across key dimensions in the model development data. This evaluation is critical for institutions to determine appropriate usage of vendor models. However, development data provided by vendors is often biased towards larger or publicly traded borrowers, as their data is more readily available and cost-effective. Additionally, vendor model developers may exclude certain types of borrowers, such as finance firms, from the development data. Therefore, it is important for model users to ensure that the vendor models are applied only to borrowers or exposures similar to the sample data used in the model's development, while excluding other borrowers for which the model has the potential to be biased. Vendors may provide guidance on when the model should not be applied or applied with extreme caution, but it is the responsibility of the model user to establish portfolio similarity through independent analysis.
Preparing internal data: Preparing the internal financial institution data, or the portfolio of intended model usage, is a key component of this comparative evaluation exercise. Firstly, this serves the purpose of identifying borrowers out of scope of the vendor model. Secondly, in instances when the model user intends to on-board a suite of models from the vendor, it is required to identify the in-scope borrowers for each of the individual models. This is relatively more challenging for smaller FIs, wherein, a single data source is generally used to store all borrower information. This contrasts with practices in larger FIs where dedicated data sources house each of the different portfolios individually Smaller FIs are therefore seen to utilize the call report codes to identify borrowers to a specific portfolio. In this entire analysis, it becomes key to observe the counts (or percentages) of borrowers to which the vendor model (or suite of vendor models) is not applicable. This represents the extent to which the vendor model(s) is not applicable to the FI's data. It therefore becomes imperative for the model user to justify high proportions in this regard and is a key aspect which necessitates continued monitoring by the FI.
Snapshot data: Model users typically conduct the portfolio similarity analysis on internal data as of a particular date. This data, commonly referred to also as snapshot or loan-tape data, should almost always be recent data representing the prevalent lending practices of the model user. In doing this comparative evaluation, it is most common for model users to understand the distribution of their internal portfolio vis-à-vis that of the development data across select predefined parameters. These parameters are either discrete, such as property types and industry sectors, or are continuous, such as DSCR and LTV. The approach to evaluating portfolio similarity for a particular parameter depends essentially on its nature.
Vendors usually ensure that the data utilized for model development covers essential parameters or dimensions. These dimensions are typically determined based on the intended use of the model's portfolio. For instance, C&I portfolios generally use industry sectors and asset sizes, while CRE portfolios utilize property types. The identification of these dimensions primarily stems from comprehending the aspects in which borrower credit risk is likely to differ across different asset classes. A table of frequently used dimensions for various portfolios is provided below.
Credit Card | Commercial Real Estate | Commercial and Industrial | Residential Mortgage |
Income | CREPI | LTD | Origination Fico |
Home Status | Seasoning factor | ROA | Indicator for Judicial States |
Number of Cards | Hotel Indicator | EBITDA | Home Price Change |
Credit Bureau Score | Vacancy factor | Total Assets | CLTV |
Age | LTV | Net Income | Property Type |
Months on Book | Judicial Indicator | Industry sector | Occupancy Type |
Bank Interest Rate | DSCR | Sales Growth | Interest Rate (Cash Flow Discounting) |
Delinquency Status | Size | Change in working capital | Spread at Origination (SatO) |
Employment Status | Origination | Cash & Marketable securities | HPI |
When dealing with discrete parameters, a comparison evaluation is usually sufficient. This involves comparing the number of borrowers or their percentages in the development data with that of the data intended for model usage. It is important for model users to ensure that the pockets in which their portfolio is concentrated are adequately represented in the development data. While there is no industry standard for the extent of this representation, it is crucial to consider the vastness of the development data. Vendor models are typically developed on large volumes of data, resulting in fractional percentages that can still yield hundreds of thousands of observations in the development data. Therefore, it is advisable for model users to focus more on non-representation. Another consideration is the use of statistical tests for comparison, such as the chi-square test. However, this is generally not feasible due to the sparse internal data that motivates the use of vendor models in the first place.
To ensure distributional similarity for continuous parameters like DSCR, LTV, and FICO, model users commonly require the vendor to provide the distribution of development data for each parameter. Depending on the borrower type, these parameters could be either DSCR or LTV for CRE borrowers, FICO for retail borrowers, or asset size for C&I borrowers. The model user then compares the distribution of these parameters in the internal data with the vendor's submitted data. Conducting statistical tests like the "t-test" is an option, but it might be hindered by the scarcity of internal data. As an alternative, model users ensure that the ranges of parameters in the internal data are subsets of those in the model development data. For example, if a model user focuses on subprime lending, they might have internal data with FICO values in the lower range (<500). In such a case, a vendor model developed on high FICO borrowers would not be a good choice. This approach can also be applied to other continuous parameters such as DSCR and LTV.
Scarce (or no) internal data: Users of vendor models often face the challenge of limited internal data for comparison with the data used by the vendor for model development. This is particularly common among smaller FIs that use vendor models to comply with IFRS9 regulations and may not have established processes for storing borrower information. As a result, conducting portfolio similarity analysis can be difficult or even impossible. However, there are alternatives to address this concern.
As a first step, model users should assess the data coverage of the vendor model in line with the FI's existing lending practices. For example, if the institution focuses on sub-prime lending, a vendor model not trained on such borrowers may be inappropriate. This approach involves comparing the institution's prevailing and future origination strategies with knowledge of the model development data. Another alternative is to use proxy data. Model users can obtain data from external data vendors that is representative of the FI's lending practices and policies. With this data, the model user can conduct a portfolio similarity analysis across various dimensions as detailed earlier in this post.
Outcomes: The vendor is responsible for testing the model's outcomes on the development data. However, it is crucial for the model user to assess the model's outcomes on the FI's internal data. This involves comparing the model's predictions on the internal data with the actual experience of the intended use portfolio to obtain different metrics that represent the model's performance. Typically, model users obtain the same metrics on internal data as those obtained by the vendor on the development data for evaluation. Nonetheless, the outcomes analysis conducted by the model user requires specific considerations for IFRS9 usage, just like the analysis done by the vendor. For IFRS9 usage, it is critical that the model user compares historical actuals with model predictions over calendar time on the internal data. In a similar vein, snapshot-based back testing becomes crucial owing to the intended model usage. Among all other validation schemes, for reasons stated previously, these 2 testing results take precedence over the others. Another critical testing scheme is the sensitivity analysis of model outcomes. Stressing model inputs from their averages in the intended data for model usage, in either direction, is a standard. This becomes more relevant with a view of model usage for IFRS9, wherein, sensitivity of the model outcomes to changes in the macroeconomic inputs is critical. Model users should therefore conduct sensitivity analysis on their internal data and evaluate the results to understand the directionality and magnitudes of the changes in model outputs.
Proxy Data: When conducting validation tests for vendor models, data insufficiency is a crucial factor to consider. Internal data limitations often prevent the development of in-house models, leading to a shortage of historical actuals that can hinder back testing of model predictions. To overcome this, vendor model users often turn to proxy data sourced from data vendors. While appropriate controls are put in place to ensure representativeness of the internal portfolio, this approach incurs additional costs that smaller FIs using vendor models for IFRS9 may find unsuitable for their cost optimization goals. In such cases, these institutions request the vendor to identify a smaller subset of development data closely aligned with the intended use of the model. Both the vendor and model user are involved in identifying this subset, which is then used to execute the model and obtain back testing results that are supposed to represent the intended portfolio of model use.
FIs must ensure validated vendor models and effective system integration are properly implemented. Regulators emphasize the importance of investing in supporting systems to ensure data and reporting integrity, controls, testing, and appropriate use. For in-house models, model developers work closely with implementation personnel to establish controls. However, vendor models pose increased risks due to propriety considerations and lack of transparent view of implementation systems, requiring added due diligence.
Personalization and Procedure risk: During the implementation of vendor models, there are two main risks that must be considered. The first is related to personalization options, which are primarily used during model implementation. Vendors provide documentation and communication of available customizations, requesting that users provide values for each. Understanding each personalization option conceptually is necessary to avoid any associated risks. The second risk is process-related, arising when deployed models use outdated financial information or macroeconomic inputs. This risk is primarily the responsibility of the model user, as the inputs to the vendor model are usually provided by the user. Inefficient query execution against user-provided data is another form of procedure risk that requires input from both the vendor and the user to understand execution inefficiencies. In-house model mitigation approaches are typically employed for vendor models, with user acceptance tests being a well-established mechanism to mitigate implementation risk. As vendor models require frequent updates, users must evaluate vendor model version controls and processes.
IFRS9 specific implementation risks: IFRS9 presents unique challenges for model implementation due to its accounting-driven regulation. The stringent timelines and high frequency of model execution pose significant risks, particularly when using vendor models, which rely on external agencies. For vendors models used in IFRS9, it is crucial to ensure that modelling data is tightly integrated into the end-to-end model execution process without manual intervention. If any changes are needed in the model output, they should be made using model overlays. Any data stream modifications require effective controls such as maker-checker processes, and regular audits. FIs must manage downtimes and upgrades/releases with clear SLAs and have policies on fallbacks for implementation delays. IFRS9 must be executed at least every quarter, with primary and secondary runs in some cases. FIs should liaise closely with vendors to avoid upgrades/releases during execution dates. This process requires rigorous streamlining and controls, which larger FIs tend to have, whereas smaller ones may face risks of inaccurate or delayed submissions.
A vendor's ability to deliver contracted services may be affected by various events, including operational disruptions, financial difficulties, provider performance failure, or business continuity failure. To ensure uninterrupted services in the event of unforeseen circumstances, business agreements between vendors and FIs should address the vendor's responsibility for maintaining contingency plans and disaster recovery, as well as backing up critical information. Such agreements should also cover the vendor's obligation to test these plans and report the results to the FI. FIs must have contingency plans that focus on critical services provided by vendors and include alternative arrangements if a vendor is unable to perform. Since IFRS9 is a sophisticated accounting standard, banks will continue to work on it until further changes. Until FIs develop their own in-house models, they will rely heavily on vendors, making a vendor's business continuity plan critical for them. In reviewing contingency plans, FIs should consider the following important checkpoints:
In conclusion, by incorporating Vendor models in your IFRS9 compliance strategy, you not only gain access to cutting-edge technologies but also benefit from the expertise of industry-leading vendors. However, it is essential to ensure that you follow the necessary steps and requirements to be allowed to use them. This article highlights the need for financial institutions to exercise caution regarding four types of risks related to vendor models: vendor-specific, institution-specific, implementation-related, and business continuity-related. This article also summarised different industry standard approaches to mitigate these risks. The considerations specific to IFRS9 usage of vendor models outlined in this post will help users, especially smaller financial institutions, to align their MRM policies and practices with regulatory guidance.
Finalyse Risk Advisory team is a trusted & reliable partner that helps you navigate the world of vendor models in IFRS9. We understand the complexities involved and have the strong expertise to guide you through the process.
Finalyse InsuranceFinalyse offers specialized consulting for insurance and pension sectors, focusing on risk management, actuarial modeling, and regulatory compliance. Their services include Solvency II support, IFRS 17 implementation, and climate risk assessments, ensuring robust frameworks and regulatory alignment for institutions. |

Check out Finalyse Insurance services list that could help your business.
Get to know the people behind our services, feel free to ask them any questions.
Read Finalyse client cases regarding our insurance service offer.
Read Finalyse blog articles regarding our insurance service offer.
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department.
Designed to provide cost-efficient and independent assurance to insurance and reinsurance undertakings
Finalyse BankingFinalyse leverages 35+ years of banking expertise to guide you through regulatory challenges with tailored risk solutions. |

Designed to help your Risk Management (Validation/AI Team) department in complying with EU AI Act regulatory requirements
A tool for banks to validate the implementation of RWA calculations and be better prepared for CRR3 in 2025
In 2027, FRTB will become the European norm for Pillar I market risk. Enhanced reporting requirements will also kick in at the start of the year. Are you on track?
Finalyse ValuationValuing complex products is both costly and demanding, requiring quality data, advanced models, and expert support. Finalyse Valuation Services are tailored to client needs, ensuring transparency and ongoing collaboration. Our experts analyse and reconcile counterparty prices to explain and document any differences. |

Helping clients to reconcile price disputes
Save time reviewing the reports instead of producing them yourself
Helping institutions to cope with reporting-related requirements
Be confident about your derivative values with holistic market data at hand
Finalyse PublicationsDiscover Finalyse writings, written for you by our experienced consultants, read whitepapers, our RegBrief and blog articles to stay ahead of the trends in the Banking, Insurance and Managed Services world |

Finalyse’s take on risk-mitigation techniques and the regulatory requirements that they address
A regularly updated catalogue of key financial policy changes, focusing on risk management, reporting, governance, accounting, and trading
Read Finalyse whitepapers and research materials on trending subjects
About FinalyseOur aim is to support our clients incorporating changes and innovations in valuation, risk and compliance. We share the ambition to contribute to a sustainable and resilient financial system. Facing these extraordinary challenges is what drives us every day. |

Finalyse CareersUnlock your potential with Finalyse: as risk management pioneers with over 35 years of experience, we provide advisory services and empower clients in making informed decisions. Our mission is to support them in adapting to changes and innovations, contributing to a sustainable and resilient financial system. |

Get to know our diverse and multicultural teams, committed to bring new ideas
We combine growing fintech expertise, ownership, and a passion for tailored solutions to make a real impact
Discover our three business lines and the expert teams delivering smart, reliable support