

The highest possible predictive power of your models
How confident are you that your risk models show what you need to see? Would your regulator agree?
How do you make sure your models are performing as expected?
Written by Nemanja Djajic, Senior Consultant
Increasing write-offs, delinquencies and bankruptcies caused by the economic crisis and inflation are placing collection departments under the spotlight in recent years. To overcome these challenges and protect financial institutions from risk, collection departments had to include advanced analytics techniques and predictive statistical modelling into their working methods.
Developing and applying scorecards for collection purposes enables banks and other financial institutions to make the best decisions on delinquent accounts and balance the costs of collection against recoverable revenues.
Using scorecards as an additional tool helps financial institutions rank customers into various categories and provides better monitoring of the observed portfolio. This approach improves risk-based decisions on delinquent accounts and potentially separates portfolio between:
For these reasons, collection scorecards can be an important and powerful banking tool for improving portfolio quality, reducing collection costs and increasing effectiveness.
Collection scorecards can be built on different levels (account, client and product level) and for different purposes (based on the internal strategy and target group), but they all share the same motivation and follow the same development algorithm. To have the highest impact of those models and be more effective in monitoring them, a financial institution should also introduce the "ageing buckets" segmentation into their collection portfolio. This segmentation is based on customers' current delinquency and has the following buckets:
Having established these "buckets", there are several collection scorecards that can be built for maximizing the impact on the internal portfolio and cost reduction:
Depending on the purpose of development, different target variables are considered for different types of collection scorecard (e.g. customer past due in observation month, increase in DPD etc.). Unlike target variables, the output of those scorecards is always the same and represents different risk categories used by the collection department for segmenting customers:
According to this output, collection managers can create different strategies that will have the highest effectiveness for each segment and consequently give the best results in terms of collected recoveries and profit.
Based on the database availability, five different types of features/variables can be created and used for the development of scorecards (having all those databases is not mandatory, scorecards can be created without any of them):
An algorithm that is used for collection scorecard development follows the standard methodology used for the regulatory models (mainly behaviour and application scorecard used for PD modelling) with few differences and less restrictive rules:
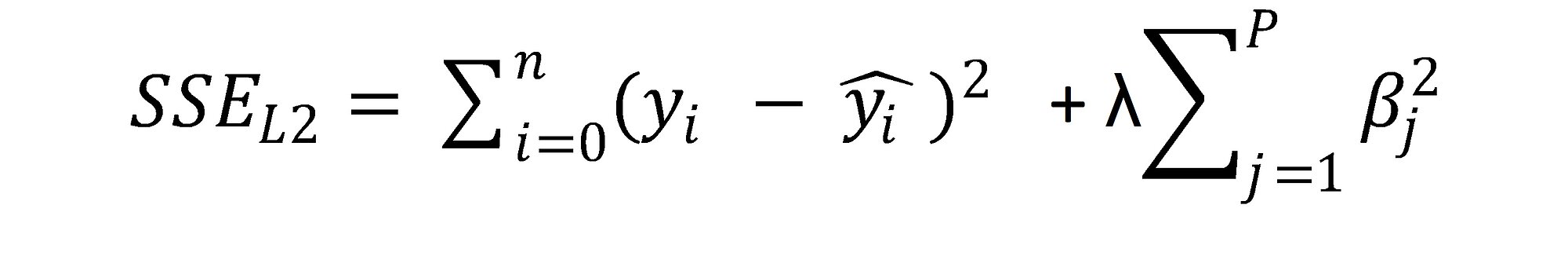
An example of a collection scorecard used to prevent customers to have at least 1 day delinquency (“Customer level scorecard that prevents regular customers to enter first bucket (1-30 DPD)”) is presented below:
COLLECTION MODEL | |||
NAME | DESCRIPTION | ESTIMATE | Pvalue |
Intercept | / | 1,5029 | <0.0001 |
max_amd_last_3M | Maximal amount due that customer had during the last 3 months. | 0,6714 | <0.0001 |
max_dpd_last_6M | Maximal number of days past due that customer had during the last 6 months. | 0,5766 | <0.0001 |
PTP_last_3M | Number of Promises-to-pay that customer made in the last 3 months. | 1,3521 | <0.0001 |
n_calls_last_6m | Number of calls to the customer during the last 6 months. | 0,8972 | <0.0001 |
dummy_rev | Dummy indicator for revolving products. | -0,5624 | 0.0026 |
dummy_missed_payment | Dummy indicator for missed payments. | 0,5584 | <0.0001 |
tot_inflow_last_3m | Total inflow on customer's CA during the last 3 months. | -1,0224 | <0.0001 |
Accordingly, since the model from example is developed using standard logistic regression algorithm, the model function is written as:
f=1,5029+ β1*F1+ β2*F2+ ⋯ β7*F7
, where βi represents estimates of the model, while Fi are used to represent variable values.
Based on the output of this function, all customers that belong to performing portfolio (in this case “bucket zero”) are separated into five risk-level buckets (very low – very high risk) – and accordingly different collection strategies are created for all of them.
RISK CATEGORY | DISTRIBUTION | STRATEGY |
Very low risk | 15% customers | No action performed |
Low risk | 25% customers | No action preformed |
Medium risk | 40% customers | No action performed, occasional collection activities |
High risk | 15% customers | Standard approach - calls, letters, reminders |
Very high risk | 5% customers | Aggressive approach - calls, letters, reminders |
There are many advantages for the banks that incorporate the scoring process in their collection activities:
The second type of non-regulatory models introduced in this article are retention models. Retention models became popular during the recent period (covid/ post covid era) mainly because competition in the financial market started to be extremely aggressive, and banks started to bid for customers to enlarge their portfolios. Following these changes in the financial market, banks, and other financial institutions, started to investigate new methods that can be applied to the portfolio for customer retention.
In general, two approaches can be used:
The second type of retention strategy – “proactive approach”, uses data analytics and collection scorecards as a basic instrument for recognising customers who are unsatisfied in a financial institution. Besides helping banks to retain existing customers, these scorecards also reduce costs because retaining existing customers usually costs less than acquiring new ones.
Since retention models have a similar framework as the collection models described in the paragraph above, the procedure will not be repeated here – instead, we will focus on the differences between the two types of scorecards.
The most significant difference between the scorecards is the target variable that is used for development. Unlike the previous scorecard, where our goal was to predict and recognise delinquent customers, here we are focusing on customers that are going to leave the bank in the near future. Accordingly, the target variable used for the model development is a binary variable that marks the customers who left the bank within 3/6 months compared to the observation period.
The output of this scorecard separates customers into five categories based on their propensity to leave the bank. For each of these categories, the financial institution should apply different proactive retention approach – no action for low-risk categories and proactive offers for customers belonging to highest-risk categories.
Databases used for retention modelling purposes are the same as those used for collection scorecards. However, one different database can provide an additional value to the retention model if it is available in an internal data warehouse:
The development process follows the standard modelling algorithm described in the collection scorecard section. For this scorecard, we can also use advanced algorithms and methods currently not in the scope of regulatory models.
In the example below you can see one of the models for retention purposes, developed by logistic regression methodology:
RETENTION MODEL | |||
NAME | DESCRIPTION | ESTIMATE | Pvalue |
Intercept | / | 0,9854 | <0.0001 |
dummy_other_bank | Dummy indicator for account in another bank. | 1,0021 | <0.0001 |
EAD_obs_month | EAD calculated in the observation month | -1,5766 | <0.0001 |
max_dpd_last_6M | Maximal number of days past due that customer had during the last 6 months. | 0,9201 | <0.0001 |
tot_inflow_last_3m | Total inflow on customer's CA during the last 3 months. | -0,5488 | <0.0001 |
tot_outflow_last_6m | Total outflow on customer's CA during the last 3 months. | 0,8005 | <0.0001 |
N_different_products_last_12m | Number of various products that customer had during the last 12 months | -0,0582 | <0.0001 |
In this case the model function can be written as:
f=0,9854+ β1*F1+ β2*F2+ ⋯ β6*F6
where βi represents estimates of the model, while Fi are used to represent variable values.
Similarly, to the collection scorecard, this model output also separates customers into five different buckets based on the propensity that they will leave the bank in the next 3/6 months.
There are many advantages to banks implementing the principles of scoring in their retention strategies and approaches:
In this article, we have presented the development of non-regulatory models and why this work is important for risk-related problems in the financial industry. Even if they are not mandatory requested by the regulators, those scorecards can significantly improve portfolio and cost control within the institutions. And although they are not directly connected with rating estimation/ECL calculation, they can support risk estimation in many other ways:
• improving relationships with the customers,
• increasing customer satisfaction,
• increasing business effectiveness
• reducing the costs.
Consequently, by using these scorecards, banks are improving their internal portfolios and decreasing the number of delinquent customers. As an additional benefit, the effectiveness of internal departments is also increased since they are able to have more precise business strategies and more efficient collection and retention processes.
Finalyse InsuranceFinalyse offers specialized consulting for insurance and pension sectors, focusing on risk management, actuarial modeling, and regulatory compliance. Their services include Solvency II support, IFRS 17 implementation, and climate risk assessments, ensuring robust frameworks and regulatory alignment for institutions. |

Check out Finalyse Insurance services list that could help your business.
Get to know the people behind our services, feel free to ask them any questions.
Read Finalyse client cases regarding our insurance service offer.
Read Finalyse blog articles regarding our insurance service offer.
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department.
Designed to provide cost-efficient and independent assurance to insurance and reinsurance undertakings
Finalyse BankingFinalyse leverages 35+ years of banking expertise to guide you through regulatory challenges with tailored risk solutions. |

Designed to help your Risk Management (Validation/AI Team) department in complying with EU AI Act regulatory requirements
A tool for banks to validate the implementation of RWA calculations and be better prepared for CRR3 in 2025
In 2027, FRTB will become the European norm for Pillar I market risk. Enhanced reporting requirements will also kick in at the start of the year. Are you on track?
Finalyse ValuationValuing complex products is both costly and demanding, requiring quality data, advanced models, and expert support. Finalyse Valuation Services are tailored to client needs, ensuring transparency and ongoing collaboration. Our experts analyse and reconcile counterparty prices to explain and document any differences. |

Helping clients to reconcile price disputes
Save time reviewing the reports instead of producing them yourself
Helping institutions to cope with reporting-related requirements
Be confident about your derivative values with holistic market data at hand
Finalyse PublicationsDiscover Finalyse writings, written for you by our experienced consultants, read whitepapers, our RegBrief and blog articles to stay ahead of the trends in the Banking, Insurance and Managed Services world |

Finalyse’s take on risk-mitigation techniques and the regulatory requirements that they address
A regularly updated catalogue of key financial policy changes, focusing on risk management, reporting, governance, accounting, and trading
Read Finalyse whitepapers and research materials on trending subjects
About FinalyseOur aim is to support our clients incorporating changes and innovations in valuation, risk and compliance. We share the ambition to contribute to a sustainable and resilient financial system. Facing these extraordinary challenges is what drives us every day. |

Finalyse CareersUnlock your potential with Finalyse: as risk management pioneers with over 35 years of experience, we provide advisory services and empower clients in making informed decisions. Our mission is to support them in adapting to changes and innovations, contributing to a sustainable and resilient financial system. |

Get to know our diverse and multicultural teams, committed to bring new ideas
We combine growing fintech expertise, ownership, and a passion for tailored solutions to make a real impact
Discover our three business lines and the expert teams delivering smart, reliable support