

Written by Ega Skura, Senior Consultant
Today’s bank lending process is characterised by uncertainty and volatility. At Finalyse, we help banks quantify their risks. We see credit scoring as a vital risk management tool, revealing untapped opportunities to create a healthy loan portfolio.
However, the complex regulatory landscape, the changes in business strategy, new technologies, and the uncertainty of the overall economy lead to the need of building robust scoring models. Quality scoring models help controlling credit risk, identifying opportunities, and lead to a new way of doing business.
A credit score is a numeric value that represents the creditworthiness of the customers. Credit scoring models are categorised into two different types: application scoring and behavioural scoring. Application scoring attempts to predict a customer’s default risk at the time an application for credit is made, based on information such as applicant demographics and credit bureau records. Behavioural scoring assesses the risk of existing customers based on their recent accounting transactions, recent financial information, including repayment performance, delinquencies, credit bureau data, and their overall relationship with the bank. By identifying the riskiest clients, the bank can take preventive actions to hedge itself against future potential loss.
Machine Learning is a method of teaching computers to parse data, learn from it, and then make a decision or prediction regarding new data. Machine Learning overlaps with statistical learning as both attempt to find and learn from patterns and trends within large datasets to make predictions.
This article discusses the benefits of applying advanced analytics in the development of behavioural scoring models. It investigates how Machine Learning techniques can be used to model the behavioural scores of consumers in each step of the development and model assessment. Some concerns regarding the usage of Machine Learning in behavioural scoring model are addressed.
Machine Learning offers various algorithms and methods that can be used during model development. There is a wide variety of Machine Learning applications related to feature selection, model fitting techniques, and model quality assessment during model development. The advantages of applying machine learning approaches consist mainly of:
Enhance the efficiency and effectiveness | Capture non-linear relationships in data | Faster decision making |
Figure nr.1: Main benefits of Machine Learning application in modelling.
The following chart summarises the contributions of machine learning in the development of the behavioural scoring model.
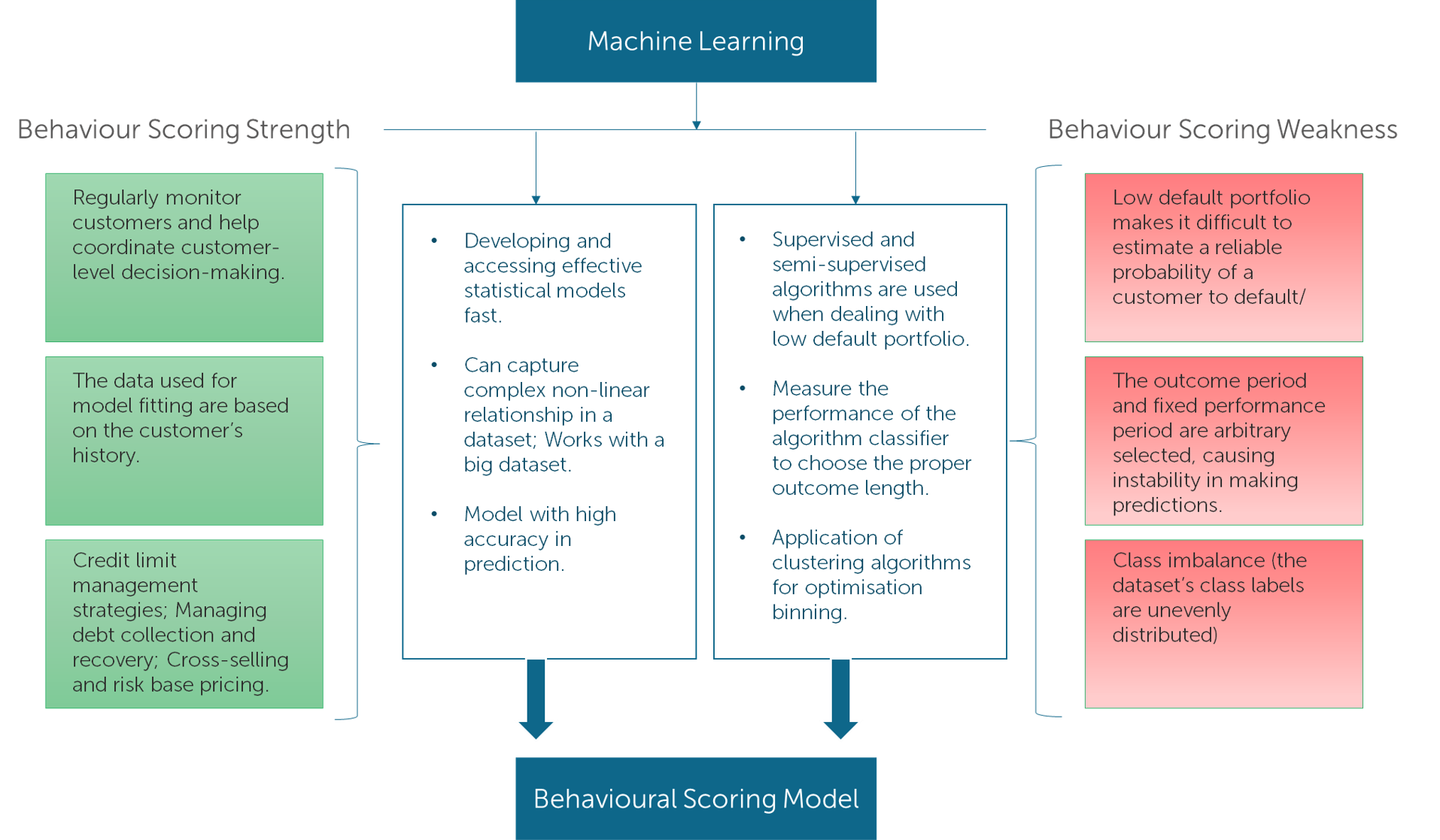
Figure Nr.2: Benefits and use of the Machine Learning techniques in behavioural scoring.
The development of the Behavioural scoring consists of the following steps: Data collection and sampling; Exploration and treatment of the data; Classification/Grouping; Model selection and model testing/evaluation.

Figure Nr.3: Behavioural scoring development steps.
Each step relates closely to those that precede and follow it and has an impact on the overall model developed, so it is important to analyse each aspect involved. Based on the implication of Machine Learning methods in Behavioural scoring model the following part explains the interaction based on 4 main domains of model development: sample creation, data engineering, model engineering, and model evaluation.
Domains | ML components |
Sample Creation
| Big data gives the opportunity to build a good model. When more data is available, increasingly complex data structures and relations can be found. ML techniques are powerful in handling complex and big data. |
Feature engineering | Usage of the ML approaches (Wrapper, Filter, and Embedded) for feature selection. Usage of ML methods for feature binning (K-means, hyperparameter optimisation). |
Model development | Usage of powerful Machine Learning algorithms produces models with high accuracy. Using explainability techniques (LIME, SHAP), ML models are not a ‘black’ box. |
Model Assessment | Statistical metrics (Confusion Matrix, Gini Coefficient, Kolmogorov Smirnov Chart, Root Mean Squared Error, etc.) are measured based on the type of the ML model. Accurate model evaluation should be based on cross-validation. |
Table Nr.1: Behavioural scoring model’s domains and Machine Learning components.
Benefits of using Machine Learning in Sample creation:
Sample creation consists of collecting data, calculating features, defining the performance window length, the outcome length, and the target feature. Machine Learning helps in making the optimal choices based on given data. |
Wrapper approach
| Filter approach
| Embedded approach
|
The principal component analysis is a ML technique for feature extraction —it creates new independent features, where each new independent feature is a combination of the “old” independent features. It determines the lines of variance in the dataset so that the first principal component has the maximum variance, thus helping in overcoming the overfitting issue by reducing the number of features. Although principal components try to cover the maximum variance among the features in a dataset, if the number of principal components is not selected with care, we may miss some information as compared to the original list of features. The proper Machine Learning approach is chosen based on the data availability.
Benefits of using Machine Learning in Feature Engineering:
Feature engineering consists of creating, selecting, and grouping features that contribute to a representative dataset creation by increasing the predictive power of machine learning algorithms. |
Train the model - this step consists of building several behavioural models and selecting the best model that fits the data and the business strategy. The learning algorithm finds patterns in the training data such that the input parameters correspond to the target. The output of the training process is a Machine Learning model that you can then use to make predictions. Machine Learning offers various algorithms, which produce models with high accuracy in the prediction. Different Machine Learning approaches could be used during the modelling part. The graph below presented the accuracy of different Machine Learning models based on a Polish corporate bankruptcy dataset. 1
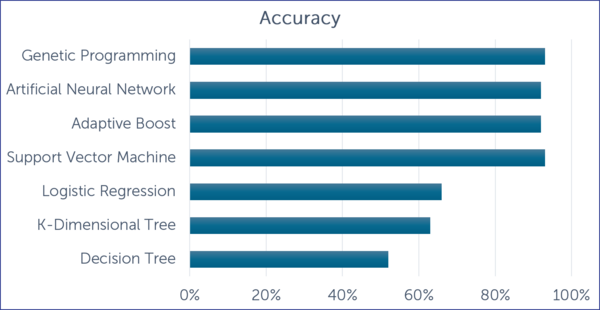
Source: Dissertation ‘Analysis of financial credit risk using Machine Learning’, Aston University, Birmingham, United Kingdom
Graph Nr.1: Accuracy rate in different Machine Learning model
Benefits of using Machine Learning in Model Engineering:
Machine learning offers powerful algorithms leading to robust models. |
Evaluating the model: in this final stage, we analyse qualitative and the quantitative aspects of the model.
Metric | Regression models | Classification models | Unsupervised models | Other |
Mean Squared Predictor Error |
|
|
|
|
Mean Squared Absolute Error | V |
|
|
|
Adjusted R Square | V |
|
|
|
Precision-Recall |
| V |
|
|
Receiver Operating Characteristic-Area Under Curve | V | V |
|
|
Accuracy | V | V |
|
|
Log-Loss |
| V |
|
|
Rand Index |
|
| V |
|
Mutual Information |
|
| V |
|
CV Error |
|
|
| V |
Heuristic methods to find K |
|
|
| V |
BLEU Score (NPL) |
|
|
| V |
Table Nr.2: Performance metrics based on the Machine Learning model.
Cross-validation is a statistical technique used during the performance assessment of a Machine Learning model. Cross validation gives a comprehensive measure of the model’s performance throughout the whole dataset by dividing it into n subsets. An average is calculated over error estimation s over all n trials to get the total effectiveness of our model. Every data point needs to be in the validation set exactly once and needs to be in a training set n-1 times.
Benefits of using Machine Learning in Model Assessment:
Model Evaluating helps in ensuring that the model performs in another dataset. To avoid overfitting cross-validation methods should be used. Also, Machine Learning techniques can be used for qualitative analysis. |
The selection and application of the proper Machine Learning algorithm which best fits with the data, the nature of the portfolio, the expected outcome, and the target feature are crucial. The usage of Machine Learning algorithms sometimes leads to the creation of overfitting models. There are two main types of error in Machine Learning models:
In Machine Learning, every model has some bias and some variance. Decreasing variance increases bias. And decreasing bias increases the variance. Some models are more prone to different types of error as summarised in the following scheme.
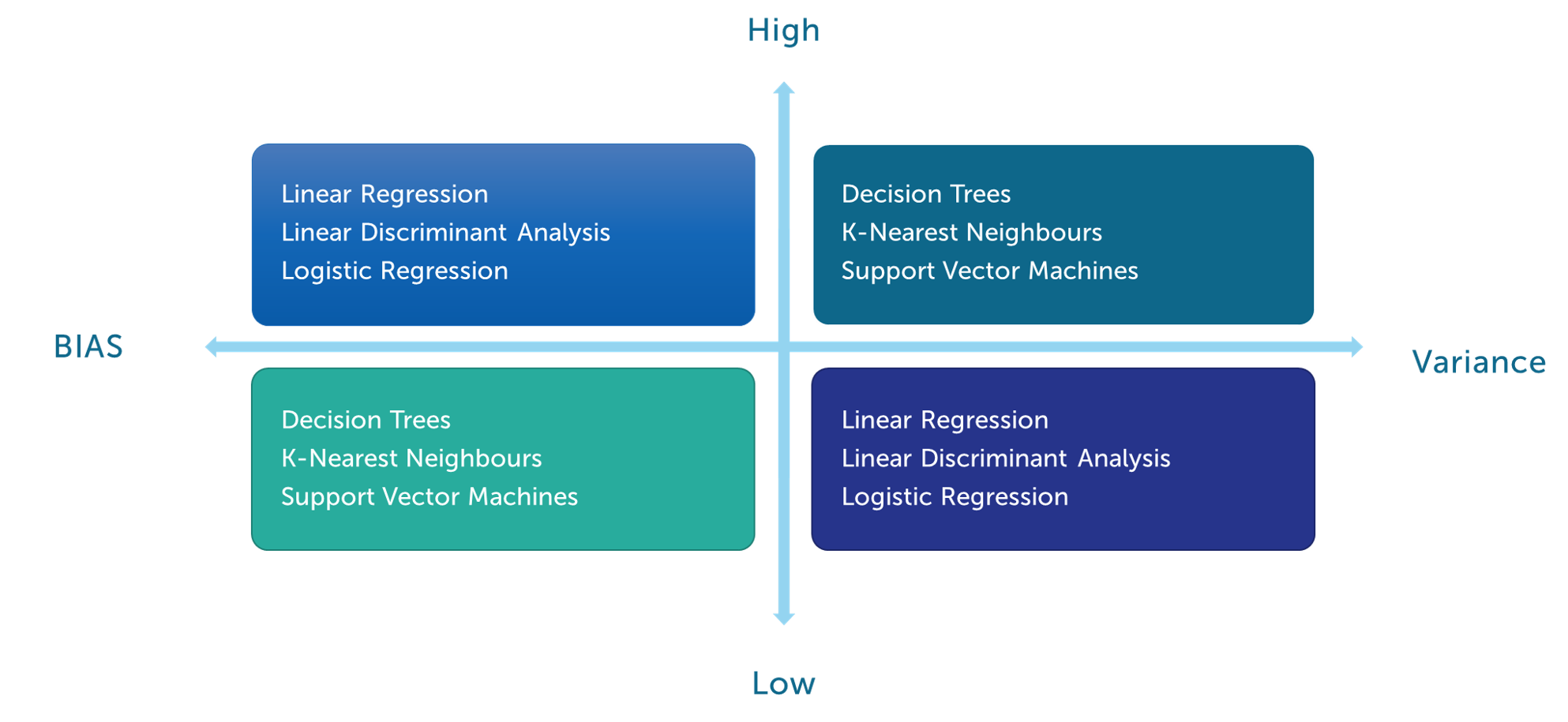
Linear algorithms are prone to high bias making them easy to learn and understand but generally less flexible. They have lower predictive performance on complex problems that fail to meet the simplifying assumptions of the algorithm.
Changing model parameters can help mitigate one type of error but it cannot solve both. Some types of hybrid models may have however the ability to mitigate both types of error. As the hybrid2 model for building behavioural scoring can be used to find an appropriate method for the feature and classifier selection, in order to use an optimal classifier and feature subset.
[2] Zhang, W., H. He, and S. Zhang, A novel multi-stage hybrid model with enhanced multi-population niche genetic algorithm: An application in credit scoring. Expert Systems with Applications, 2019. 121: p. 221-232
It is important to use cross-validation methods to eliminate the overfitting issue. Using cross-validation, the dataset can be spit n times. The next step is to train each dataset, calculate the accuracy for each dataset, and an average of the metrics. This method requires somewhat more computations than regular splitting. But it returns much stronger evaluation metrics. Before selecting any Machine Learning method, it is worth knowing the pros and cons of applying them in Behavioural scoring modelling. The following table summarizes merits of some Machine Learning algorithms:
Machine Learning Algorithm | Description | Pros | Cons | |
Logistic Regression | Estimation of the relationship between variables to predict the future outcome. | Outputs have probabilistic interpretation, and the algorithm can be regularized to avoid overfitting. Logistic models can be updated easily with new data using stochastic gradient descent. | Logistic regression tends to underperform when there are multiple or non-linear decision boundaries. They are not flexible enough to naturally capture more complex relationships. | |
Decision Trees | Decision trees are rule-based learning methods.
| Easy to implement and understand as they require data normalization and the model is not affected by missing values.
| A small change in the data can cause a large change in the structure of the decision tree causing instability.
| |
Support Vector Machine | SVMs finds optimal hyperplanes that best separate the dataset. A hyperplane is chosen such that the ‘margin’ between the plane and data points of different classes on either side is maximized. | High accuracy model with a high number of features. | The algorithm is prone to over-fitting, if the number of features is significantly greater than the number of samples. Also, SVM models require a big dataset. | |
Neutral Network | NNs are sets of algorithms which try to recognize the patterns in the data and help cluster and classify the data. | Neural networks are good to model with nonlinear data with a large number of inputs. It works by splitting the problem of classification into a layered network of simpler elements. | Neural networks are black boxes, too often, we cannot know how much each independent variable is influencing the dependent variables. | |
Gradient Boosting | GB builds an ensemble of successive trees with each tree learning and improving on the previous. | No data pre-processing required - often works great with categorical and numerical values as is. | Many parameters influence the Behavioural of the approach (number of iterations, tree depth, regularization parameters, etc.). This requires a large grid search during features allocation and transformation. | |
Table Nr.4: Pros and Cons in using Machine Learning algorithms in modelling.
Machine Learning techniques can bring great added value to building statistical models. This document aimed to show some concepts of how Machine Learning components can be used in the context of behavioral scoring model and to shortly describe some techniques that can be employed. Each technique should be applied to conform to the data structure, size, and composition. The implication of the Machine Learning methods can be used in each step of the behavioural model development to ensure an adequate process for the overall model development. This article shows that the usage of the advanced Machine Learning methods could result in behavioural scoring models with high accuracy in predictive power but every aspect of the model development should be considered carefully in order to adapt the proper Machine Learning algorithm. Knowing the pros and cons of each algorithm can help in choosing the best approach in line with the model purpose and model usage.
Finalyse InsuranceFinalyse offers specialized consulting for insurance and pension sectors, focusing on risk management, actuarial modeling, and regulatory compliance. Their services include Solvency II support, IFRS 17 implementation, and climate risk assessments, ensuring robust frameworks and regulatory alignment for institutions. |

Check out Finalyse Insurance services list that could help your business.
Get to know the people behind our services, feel free to ask them any questions.
Read Finalyse client cases regarding our insurance service offer.
Read Finalyse blog articles regarding our insurance service offer.
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department.
Designed to provide cost-efficient and independent assurance to insurance and reinsurance undertakings
Finalyse BankingFinalyse leverages 35+ years of banking expertise to guide you through regulatory challenges with tailored risk solutions. |

Designed to help your Risk Management (Validation/AI Team) department in complying with EU AI Act regulatory requirements
A tool for banks to validate the implementation of RWA calculations and be better prepared for CRR3 in 2025
In 2027, FRTB will become the European norm for Pillar I market risk. Enhanced reporting requirements will also kick in at the start of the year. Are you on track?
Finalyse ValuationValuing complex products is both costly and demanding, requiring quality data, advanced models, and expert support. Finalyse Valuation Services are tailored to client needs, ensuring transparency and ongoing collaboration. Our experts analyse and reconcile counterparty prices to explain and document any differences. |

Helping clients to reconcile price disputes
Save time reviewing the reports instead of producing them yourself
Helping institutions to cope with reporting-related requirements
Be confident about your derivative values with holistic market data at hand
Finalyse PublicationsDiscover Finalyse writings, written for you by our experienced consultants, read whitepapers, our RegBrief and blog articles to stay ahead of the trends in the Banking, Insurance and Managed Services world |

Finalyse’s take on risk-mitigation techniques and the regulatory requirements that they address
A regularly updated catalogue of key financial policy changes, focusing on risk management, reporting, governance, accounting, and trading
Read Finalyse whitepapers and research materials on trending subjects
About FinalyseOur aim is to support our clients incorporating changes and innovations in valuation, risk and compliance. We share the ambition to contribute to a sustainable and resilient financial system. Facing these extraordinary challenges is what drives us every day. |

Finalyse CareersUnlock your potential with Finalyse: as risk management pioneers with over 35 years of experience, we provide advisory services and empower clients in making informed decisions. Our mission is to support them in adapting to changes and innovations, contributing to a sustainable and resilient financial system. |

Get to know our diverse and multicultural teams, committed to bring new ideas
We combine growing fintech expertise, ownership, and a passion for tailored solutions to make a real impact
Discover our three business lines and the expert teams delivering smart, reliable support