

Written by Barend Janse Van Rensburg, Consultant
Machine learning has shown a capacity for considerable improvements in several business areas, and its usage in the financial industry will continue to be explored. However, In the credit risk sector, financial institutions have been hesitant to implement ML into banks’ IRB models to forecast regulatory capital requirements.
This article examines the challenges and potential opportunities presented by machine learning when used to compute regulatory capital for credit risk using internal ratings-based (IRB) models. It also gives an overview of machine learning techniques that can be utilised for IRB modelling, as well as the results that can be expected.
In 1988 the Basel Committee on Banking Supervision (BCBS) published the so-called Basel I covering capital requirements for credit risk and appropriate risk-weighting of assets. Basel II, the new capital framework, superseded the Basel I framework in 2004, introducing three main pillars:
- Minimum capital requirements, which concern the maintenance of regulatory capital estimated for credit risk, operational risk, and market risk;
- Internal and supervisory assessments of an institution's capital sufficiency; and
- Market discipline and sensible banking practices can both benefit from increased transparency.
Basel II provided banks with three options for determining regulatory capital requirements for credit risk, namely (i) the standardised approach, (ii) the Foundation Internal Rating-Based Approach (F-IRB), and (iii) Advanced IRB (A-IRB). These options remained essentially the same with some minor adjustments in 2010s Basel III and 2017s Basel IV. However, since then, banks have not used materially different IRB modelling methodologies to estimate credit risk. Regulators and supervisors concentrated on strengthening the definition of core concepts to ensure the comparability of the estimates given by different models. This meant that the significance and challenges of advanced technologies such as machine learning (ML) and artificial intelligence (AI) were underappreciated
The Report on BD&AA, released by the EBA in January 2020, stated that advanced analytics include ‘predictive and prescriptive analytical techniques, often using AI and ML in particular, and are used to understand and recommend actions based on the analysis of high volumes of data from multiple sources, internal or external to the institution’.
Machine Learning (ML) can be defined as a method of teaching computers to parse, learn from, and then make a decision or prediction regarding new data. Machine Learning overlaps with statistical learning as both attempt to find and learn from patterns and trends within large datasets to make predictions.
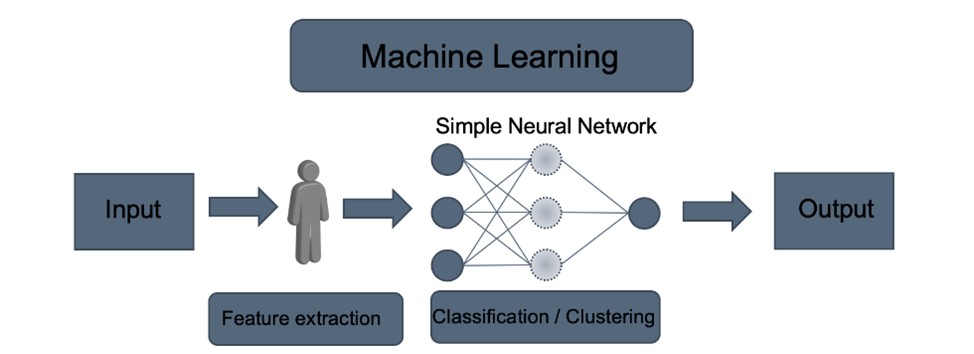
Machine learning encompasses a broad array of models of varying degrees of complexity. Linear regressions, straightforward models with a minimal number of parameters, are an example of simple ML models. Deep neural networks are an example of the opposite extreme of the complexity scale. The number of factors in these models might reach millions, rendering understanding and application difficult. However, the term Machine Learning is primarily used to denote the more complicated models. This has long been the case in the financial sector, where linear and logistic regressions have been frequently applied, but the term machine learning is reserved for the more innovative models.
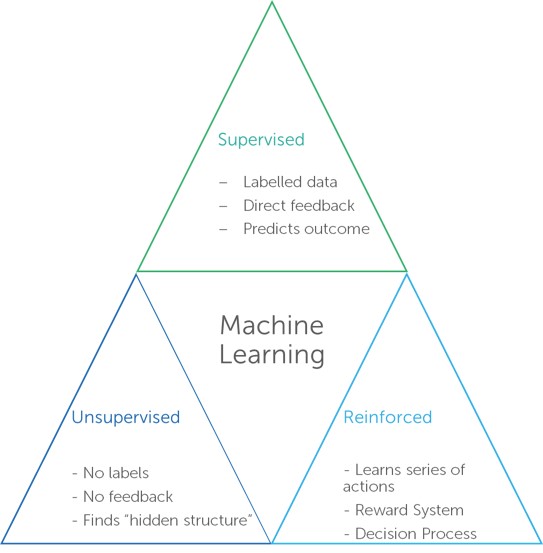
Depending on the purpose of the model and the type of data necessary, a variety of learning paradigms can be employed to train ML models. The three most prevalent learning paradigms are currently:
- Supervised learning: the algorithm learns model-building rules from a labelled dataset and applies these rules to predict labels on incoming input data.
- Unsupervised learning: the algorithm learns from an unlabelled input training dataset with the purpose of understanding the data distribution and/or finding a more efficient representation of it.
- Reinforcement learning: instead of learning from a training dataset, the algorithm learns by interacting with the environment. In addition, unlike supervised learning, reinforcement learning does not need the use of labelled input/output pairs. By trial and error, the algorithm learns to do a certain task.
To date, the adoption of ML-driven IRB models has been unenthusiastic – or non-existent in the case of many European banks. According to the IIF 2019 report, credit decisions/pricing is the most popular application of machine learning in credit risk, followed by credit monitoring and collections, restructuring and recovery. Machine Learning is all but avoided in regulatory domains like credit risk capital requirements, stress testing, and provisioning. Regulatory restrictions are seen as a hurdle for the deployment of ML models in this area, as they are more difficult to analyse and explain.
The usage of ML in IRB modelling has been limited to supplementing the traditional models for calculating capital requirements. Examples of where machine learning techniques are currently applied in IRB models to meet CRR requirements are:
- Model validation: Machine learning models are used to create challenger models that serve as a comparison to the standard model for calculating capital requirements.
- Data quality: Machine learning techniques can be used to improve data quality and can be used to analyse rich datasets.
- Variable selection: ML could be used to find explanatory factors and combinations in a large dataset with good prediction capacities.
- Risk differentiation: ML models can be used as a module for risk differentiation in the probability of default (PD) model.
However, the following section outlines the challenges for the ML models to be utilised as primary IRB models for prediction (e.g., risk differentiation).
The major difficulty of ML models is their complexity, which leads to challenges in:
ML models may provide issues or offer solutions unique to the context in which they are deployed. The following are the key areas of application:
- Risk differentiation;
- Risk quantification;
- Model validation;
- Other fields, such as data preparation or the application of machine learning models for credit risk mitigation.
The intricacy and interpretability of some ML models may represent extra hurdles for institutions developing compliant IRB models, depending on the context of their use. However, this does not rule out the possibility of using these models.
ML models for risk differentiation face several unique issues, including those linked to the following CRR requirements:
Requirement | Challenges |
The definition and assignment criteria to grades or pools |
|
Complementing human judgement |
|
Documentation |
|
Using the ML model for risk quantification has its own set of issues, including those linked to the following CRR requirements:
Requirement | Challenges |
Concerning the estimation process, the plausibility and intuitiveness of the estimates |
|
Length of the underlying historical observation |
|
Validation of ML models may provide some unique issues. There are two categories of challenges:
Requirement | Challenges |
Interpreting/resolving the findings |
|
Validation of the core model performance |
|
Requirement | Challenges |
Corporate Governance |
|
The implementation process |
|
Categorisation of model changes |
|
The use of big and unstructured data |
|
With some effort, machine learning models could improve the IRB models whilst meeting all prudential standards. The following are some examples of areas where machine learning models could be useful:
- Improving risk differentiation through improving model discriminatory power and offering valuable tools for identifying all key risk drivers and their relationships. ML models could also be used to improve portfolio segmentation, construct robust models across geographical and industrial sectors/products, and make data-driven decisions that balance data availability with model granularity requirements. Furthermore, machine learning models may aid in the confirmation of data features chosen by expert judgment in 'conventional' model creation, providing a data-driven viewpoint on the feature selection process.
- Improving risk quantification by increasing model predictive power and recognising material biases, as well as offering tools for identifying recovery patterns in LGD models. ML models could potentially aid in the calculation of the necessary modifications.
- Improving data collecting and preparation processes, such as input data cleansing, data treatment and data quality checks. Through unsupervised learning approaches, ML models could be effective for analysing representativeness. Furthermore, machine learning models could be used to discover outliers and correct errors. In addition, unstructured data (e.g. qualitative data like business reports) could be employed with ML models, expanding the data sets that can be used for parameter estimation.
- Improving credit risk mitigation approaches, including the use of machine learning algorithms for collateral valuation through haircut models.
- Providing reliable systems for model validation and monitoring where model challengers or a supporting analysis for alternative assumptions or techniques could be generated using machine learning models.
Since machine learning models are more complex than traditional techniques like regression analysis or simple decision trees, current risk management procedures and governance frameworks may require further enhancements.
Most concerns relate to the ML models' complexity and reliability, with the main decisive challenges appearing to be the interpretability of the results, governance, with a particular focus on increased staff training needs, and the difficulty in evaluating a model's generalisation capacity (i.e. avoiding overfitting).
To overcome these challenges, several techniques have been developed that provide insight into a model's fundamental logic. The following are some of the most commonly utilised techniques:
ML models may be useful if they provide adequate monitoring, validation, and explanation of the process and model results. Strong institutional awareness of their IRB models is critical, and this is especially true when machine learning models are utilised for regulatory reasons. ML can be applied to a variety of tasks and levels, including data preparation, risk differentiation, risk quantification, and internal validation.
All of the following criteria apply when ML models are to be used for risk differentiation and risk quantification.
If an institution seeks to employ machine learning models for regulatory capital, all relevant stakeholders should have a sufficient understanding of how the model works. The EBA recommends that institutions make certain that:
Furthermore, banks should avoid unnecessary complexity in the modelling approach. Institutions should refrain from:
Institutions should also do the following to ensure that the model is accurately translated and understood:
When machine learning techniques are combined with human judgment, a thorough grasp of the model is essential. Particularly the Staff in charge should be able to assess the modelling assumptions when human judgment is applied in the development of the model.
When Machine Learning models are updated frequently, the institution must thoroughly investigate and monitor the rationale for the frequent updates. Furthermore, institutions should always compare modifications to the most recent approved model to ensure that a high frequency of minor changes does not result in an unnoticed material change within a given period of time. As a result, institutions must assess the benefits of automatic and regular updates to their IRB model against the hazards.
A reliable validation is especially critical for complicated ML models with limited explainability or for often updated models. It is suggested that institutions pay attention to:
i. Overfitting issues: Overfitting the development sample is a common problem with machine learning models. As a result, financial institutions should pay close attention to comparing model performance evaluated within the development sample to model performance measured using out-of-sample and out-of-time samples.
ii. Challenging the model design: The hyperparameters used to describe the model's structure and to tailor the learning algorithm are frequently based on human judgment. As a result, the validation unit should pay special attention to the rationale for selecting these hyperparameters.
iii. Representativeness and data quality issues: When large datasets are fed into machine learning techniques for risk differentiation and quantification, data quality must be ensured. When these data are external data, institutions should pay special attention to determining the external data's representativeness in relation to the application portfolio. When employing unstructured data, institutions should take extra precautions to ensure that the data is accurate, full, and suitable.
iv. Analysis of the stability of the estimates: It is useful to analyse both the stability:
It is advised that institutions ensure that there are clear rules and documentation. Institutions should use a comprehensive set of checks and controls to guarantee that the methodology used to analyse data is appropriate.
Machine learning has a well-established place in the future of the banking and finance business, and it's believed that risk management will use machine learning approaches to improve their capabilities as well. Despite being criticised for acting like a black box, machine learning approaches have the potential to analyse large amounts of data without being bound by distribution assumptions and provide significant value in exploratory analysis, classification, and predictive analytics.
This may change the risk management landscape. Machine learning, which has been regarded as one of the technologies with significant risk management implications, can help risk managers construct more accurate risk models by recognising complicated, nonlinear patterns in vast datasets.
Given its size and scope, machine learning requires greater collaboration between the industry and regulators to guarantee that it protects clients without limiting innovation in the financial sector. Because of the risk-averse nature of the financial industry, pilot programs that investigate and test novel technologies should be encouraged by legislators and supervisors.
Finalyse InsuranceFinalyse offers specialized consulting for insurance and pension sectors, focusing on risk management, actuarial modeling, and regulatory compliance. Their services include Solvency II support, IFRS 17 implementation, and climate risk assessments, ensuring robust frameworks and regulatory alignment for institutions. |

Check out Finalyse Insurance services list that could help your business.
Get to know the people behind our services, feel free to ask them any questions.
Read Finalyse client cases regarding our insurance service offer.
Read Finalyse blog articles regarding our insurance service offer.
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department.
Designed to provide cost-efficient and independent assurance to insurance and reinsurance undertakings
Finalyse BankingFinalyse leverages 35+ years of banking expertise to guide you through regulatory challenges with tailored risk solutions. |

Designed to help your Risk Management (Validation/AI Team) department in complying with EU AI Act regulatory requirements
A tool for banks to validate the implementation of RWA calculations and be better prepared for CRR3 in 2025
In 2027, FRTB will become the European norm for Pillar I market risk. Enhanced reporting requirements will also kick in at the start of the year. Are you on track?
Finalyse ValuationValuing complex products is both costly and demanding, requiring quality data, advanced models, and expert support. Finalyse Valuation Services are tailored to client needs, ensuring transparency and ongoing collaboration. Our experts analyse and reconcile counterparty prices to explain and document any differences. |

Helping clients to reconcile price disputes
Save time reviewing the reports instead of producing them yourself
Helping institutions to cope with reporting-related requirements
Be confident about your derivative values with holistic market data at hand
Finalyse PublicationsDiscover Finalyse writings, written for you by our experienced consultants, read whitepapers, our RegBrief and blog articles to stay ahead of the trends in the Banking, Insurance and Managed Services world |

Finalyse’s take on risk-mitigation techniques and the regulatory requirements that they address
A regularly updated catalogue of key financial policy changes, focusing on risk management, reporting, governance, accounting, and trading
Read Finalyse whitepapers and research materials on trending subjects
About FinalyseOur aim is to support our clients incorporating changes and innovations in valuation, risk and compliance. We share the ambition to contribute to a sustainable and resilient financial system. Facing these extraordinary challenges is what drives us every day. |

Finalyse CareersUnlock your potential with Finalyse: as risk management pioneers with over 35 years of experience, we provide advisory services and empower clients in making informed decisions. Our mission is to support them in adapting to changes and innovations, contributing to a sustainable and resilient financial system. |

Get to know our diverse and multicultural teams, committed to bring new ideas
We combine growing fintech expertise, ownership, and a passion for tailored solutions to make a real impact
Discover our three business lines and the expert teams delivering smart, reliable support