

Written by Sayali Kulkarni, Consultant
Maciej Smółko, Consultant
Edited by Augustin de Maere, Managing Consultant
Machine learning is today’s buzzword and it has gone through some phenomenal changes over the last few years. Starting as academic and research-oriented domain, we have seen widespread industry adoption across diverse domains including E-commerce, retail, Banking, Insurance, healthcare etc. Despite widespread adoption, machine learning models remain mostly black boxes. Hence it is essential to have techniques for explaining these black boxes in an interpretable manner.
Should we just trust the machine learning model?
Or should we seek for the explanation of why it made a certain decision?
In “Little Britain”, a British sketch comedy show, a bank worker responds to customer requests by typing them into the computer and subsequently responding with "computer says no" without providing any explanations of the decision. In the world of more and more advanced AI systems it becomes clear that such attitude will not endure, as regulators demand more transparency to avoid possible biases based on factors as gender or race.
The concept of explainability is usually used in contrast to the “black box” term, that is a system e.g. algorithm where the user is only aware about the input and the output but has no insight into what is happening within the algorithm.
When it comes to methods such as machine learning, neural networks or AI the given systems can lack transparency or, what is worse, they can contain unconscious biases of their creators. The issue is present also in ‘classical’ models, but we already have some relatively well-established methods to detect them.
That is a big problem. And it is where the “model explainability” comes into place.
The term explainability is sometimes used interchangeably with interpretability, but the most experienced analysts underline the subtle difference between the two. When the model is interpretable then human can explain what that model did. However, when the model is explainable then we can go a step further – we should be able not only explain what happened but also why – which variables contributed the most to the result, which relations in data were crucial and how only causal relationships were picked up. Only then we can call a model auditable and able to gain a trust of users.
Restricting ourselves to simple linear models is a one approach but at expense of accuracy. To make these models more accurate we often make them less explainable. To address this issue, we can use Model agnostic methods that allow usage of complex models whilst maintaining the explainability. Also, it potentially offers a “one size fits all” approach to cover the explainability topic for a large variety of Machine Learning models.
Model-agnostic methods are completely independent of the underlying machine learning models and that is their biggest advantage.
Usually we evaluate multiple machine learning models like Random forest, XGBoost, GBM or deep neural networks to solve a single problem. When comparing models in terms of local interpretability, it is easier to work with model-agnostic explanations, because the same method can be used for any type of model.
It is important to understand the underlying mechanics of these techniques, and any potential pitfalls associated with them. In this article we will see widely used methods like LIME, SHAP and CP profiles.

By generating an artificial dataset around the particular observation, we can try to approximate the predictions of Black box model locally using simple interpretable model. Then this model can be served as ‘’local explainer’’ for the Black box model.
However the representation would vary with the type of data. Lime supports Text data, Image data and Tabular type of data:
This article is focused on tabular data. Tabular data is data that comes in tables, with each row representing an instance and each column a feature.

The output of LIME in Python looks like this:
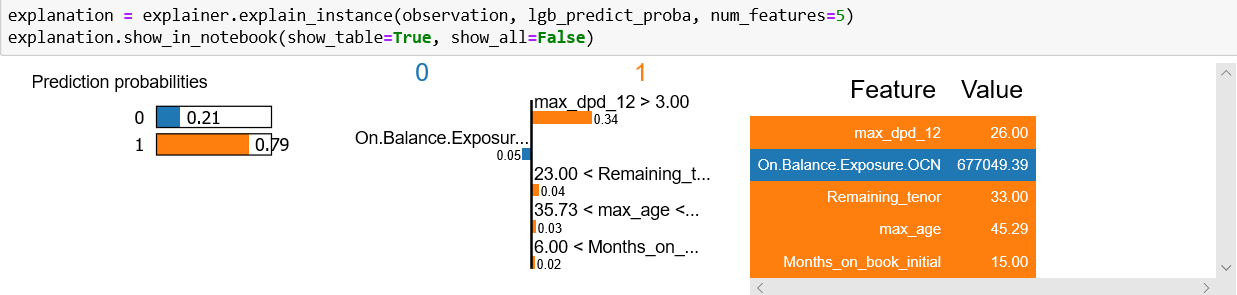
We see that Python gives us output is in 3 parts which can be interpreted as follows:
The reliability of this prediction can be given by R2
SHAP (SHapley Additive exPlanations) is the extension of the Shapley value, a game theory concept introduced in 1953 by mathematician and economist Lloyd Shapley. SHAP is an improvement of the method for machine learning model explainability study. It is used to calculate the impact of each part of the model to the final result. The concept is a mathematical solution for a game theory problem – how to share a reward among team members in a cooperative game?
Shapley value assumes that we can compute value of the surplus with or without each analysed factor. Algorithm estimates the value of each factor by assessing the values of its ‘coalitions’. In case of Machine Learning the ‘surplus’ is a result of our algorithm and co-operators are different input values.
The goal of SHAP is to explain the prediction by computing the contribution of each feature to the final result.
SHAP procedure can be applied e.g. using dedicated Python shap library. As an analyst we can choose from three different explainers – functions within the shap library.
We run the process always for a given observation. The starting point for the analysis is the average result in our data set. SHAP checks how the deviation from the average was impacted by each variable. In R you can find similar solutions in shapper and XGBoost libraries.
SHAP explanation force plot in Python looks like this:

The above fig. shows that this particular customer has higher risk of default with the probability of 0.84. Days past due in past 12 months being higher( 144 days) and On balance exposure also being on the higher side increases his predicted risk of default.
The prediction starts from the baseline. The baseline for Shapley values is the average of all predictions.
Each feature value is a force that either increases or decreases the prediction. Each feature contributing to push the model output from the base value to the model output. Features pushing the prediction higher are shown in red, those pushing the prediction lower are in blue.
Ceteris paribus is a Latin phrase used to describe the circumstances when we assume aspects other than the one being studied to remain constant.
In particular, we examine the influence of each explanatory variable, assuming that effects of all other variables are unchanged. Ceteris-paribus (CP) profiles are one-dimensional profiles that examine the curvature across each variable. In essence it shows a conditional expectation of the dependent variable for the particular independent variable Ceteris-Paribus profiles are also a useful tool for sensitivity analysis.
We can make local diagnostics with CP profiles using Fidelity plot. The idea behind fidelity plots is to select several observations that are closest to the instance of interest. Then, for the selected observations, we plot CP profiles and check how stable they are. Additionally, using actual value of dependent variable for the selected neighbours, we can add residuals to the plot to evaluate the local fit of the model.
Local-fidelity plots may be very helpful to check if the model is locally additive and locally stable but for a model with a large number of explanatory variables we may end up with a large number of plots. The drawback is these plots are quite complex and lack objective measures of the quality of the model fit. Thus, they are mainly suitable for an exploratory analysis.
We have arrived at the end of this article. I hope it brings some light to your understanding of LIME, SHAP and CP- Profiles and how can they be used to explain machine learning models. In conclusion: Lime is very good for getting a quick look at what the model does but has consistency issues. Shapley value delivers a full explanation making it it a lot more precise than Lime.
Aside from its practical usefulness, explainability will be ever more crucial for an additional reason: regulators in the European Union and the United States (as well as number of other countries) are pushing more and more boldly for the so-called “right to explanation” which is supposed to, among other things, protect its citizens from gender or race biased decisions when applying for a loan.
Finalyse InsuranceFinalyse offers specialized consulting for insurance and pension sectors, focusing on risk management, actuarial modeling, and regulatory compliance. Their services include Solvency II support, IFRS 17 implementation, and climate risk assessments, ensuring robust frameworks and regulatory alignment for institutions. |

Check out Finalyse Insurance services list that could help your business.
Get to know the people behind our services, feel free to ask them any questions.
Read Finalyse client cases regarding our insurance service offer.
Read Finalyse blog articles regarding our insurance service offer.
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department.
Designed to provide cost-efficient and independent assurance to insurance and reinsurance undertakings
Finalyse BankingFinalyse leverages 35+ years of banking expertise to guide you through regulatory challenges with tailored risk solutions. |

Designed to help your Risk Management (Validation/AI Team) department in complying with EU AI Act regulatory requirements
A tool for banks to validate the implementation of RWA calculations and be better prepared for CRR3 in 2025
In 2027, FRTB will become the European norm for Pillar I market risk. Enhanced reporting requirements will also kick in at the start of the year. Are you on track?
Finalyse ValuationValuing complex products is both costly and demanding, requiring quality data, advanced models, and expert support. Finalyse Valuation Services are tailored to client needs, ensuring transparency and ongoing collaboration. Our experts analyse and reconcile counterparty prices to explain and document any differences. |

Helping clients to reconcile price disputes
Save time reviewing the reports instead of producing them yourself
Helping institutions to cope with reporting-related requirements
Be confident about your derivative values with holistic market data at hand
Finalyse PublicationsDiscover Finalyse writings, written for you by our experienced consultants, read whitepapers, our RegBrief and blog articles to stay ahead of the trends in the Banking, Insurance and Managed Services world |

Finalyse’s take on risk-mitigation techniques and the regulatory requirements that they address
A regularly updated catalogue of key financial policy changes, focusing on risk management, reporting, governance, accounting, and trading
Read Finalyse whitepapers and research materials on trending subjects
About FinalyseOur aim is to support our clients incorporating changes and innovations in valuation, risk and compliance. We share the ambition to contribute to a sustainable and resilient financial system. Facing these extraordinary challenges is what drives us every day. |

Finalyse CareersUnlock your potential with Finalyse: as risk management pioneers with over 35 years of experience, we provide advisory services and empower clients in making informed decisions. Our mission is to support them in adapting to changes and innovations, contributing to a sustainable and resilient financial system. |

Get to know our diverse and multicultural teams, committed to bring new ideas
We combine growing fintech expertise, ownership, and a passion for tailored solutions to make a real impact
Discover our three business lines and the expert teams delivering smart, reliable support