


Sehaj is an accomplished solution architect with over 10 years of experience in Risk Management and Decision Analytics. His expertise covers a wide range of areas, including Data warehousing, Solution design, ETL & Data architecture. He is an active contributor to the data modeling workstream of ECB’s BIRD initiative. As a solution architect and technical lead, Sehaj has been involved in several significant projects like implementing a Basel IV compliant Credit Risk Weighted Asset calculator using SAS EG, leading a team that implemented a new Operational Risk management tool integrated with Hadoop and redesigning & implementing a BCBS-239 compliant risk reporting module. He is also a skilled project manager with excellent communication skills.

Hugo is a Principal Consultant in Finalyse Brussels. He has a wide knowledge and expertise in financial products, valuation algorithms, reporting and regulatory issues. He combines in depth knowledge of banking financial risks and regulations with a wide understanding of the data, IT infrastructure and processes underneath. Hugo has been involved in multiple Risk and Regulatory Reporting implementation projects such as RWA calculation for credit risk, EAD calculation under SACCR, automation of internal reports for ALM and implementation of data governance to comply with BCBS239. Hugo is an experienced Agile project manager who stands-out for his dynamism, adaptability and interpersonal skills.
As Banks and Financial Institutions drive towards compliance with BCBS-239 principles, documenting data lineage and mapping process flows for relevant risk metrics forms a big part of the overall requirements. However, we cannot fail to notice that these data transformation and aggregation processes are often needlessly inefficient and complex. This can be pinned down to the increase in the complexity and the sheer number of reporting requirements by regulators over the years. This has in-turn resulted in a buildup of technical debt in the overall architecture and design of the solutions that facilitate the computation of said metrics.
The natural next step in the journey towards more accurate and precise risk reporting is to leverage BCBS-239 features like data lineages, glossaries, reference datasets etc. to create an enterprise-wide integrated data layer that can source, transform, enrich, and store all underlying facts and dimensions in a manner that makes sense to Risk analysts and managers.
The idea behind building a new data layer is to introduce a degree of normalisation of data by organising all source information into a standardised format supported by a logical data model that can cater for all downstream calculation and reporting needs. This information can then be further enriched semantically by marrying it to a centralised data glossary and reference data. This is a superior way of organising information in your data warehouse and can eliminate all duplication of transformation rules while also simplifying the control framework required to maintain data integrity across the risk reporting process.
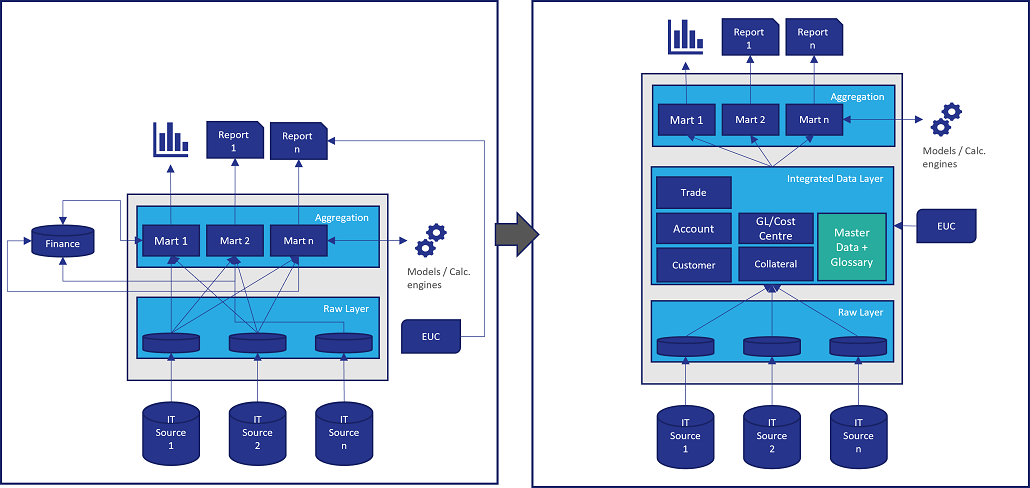
The European Central Bank’s BIRD initiative intends to tackle the same problem. Recognising the increasing complexity and volume of regulatory reporting, the service intends to create an integrated dictionary – completed with an overarching logical data model that Banks and FIs can map their physical data elements to with the objective of standardising their reporting frameworks. The scope of BIRD is not just limited to risk reporting but encompasses the entire breadth of regulatory reporting for Banks.
The BIRD data model also intends to function as an all-encompassing input layer for ECB’s proposed Integrated Reporting Framework (IReF), which will integrate the European regulator’s statistical requirements for Banks into a single standardised reporting framework applicable across the Euro area (e.g.: BSI and MIR statistics, SHS-S, AnaCredit and FinRep). It needs to be noted that BIRD is not a regulatory requirement but merely a free-to-use service. However, as the project itself highlights, the benefits of modelling a data management framework on its design principles are hard to understate. Building an Integrated Data Layer incorporating BIRD’s design principles and data models is a sure-fire way to eliminate redundancies and improve the overall quality and accuracy of your data.
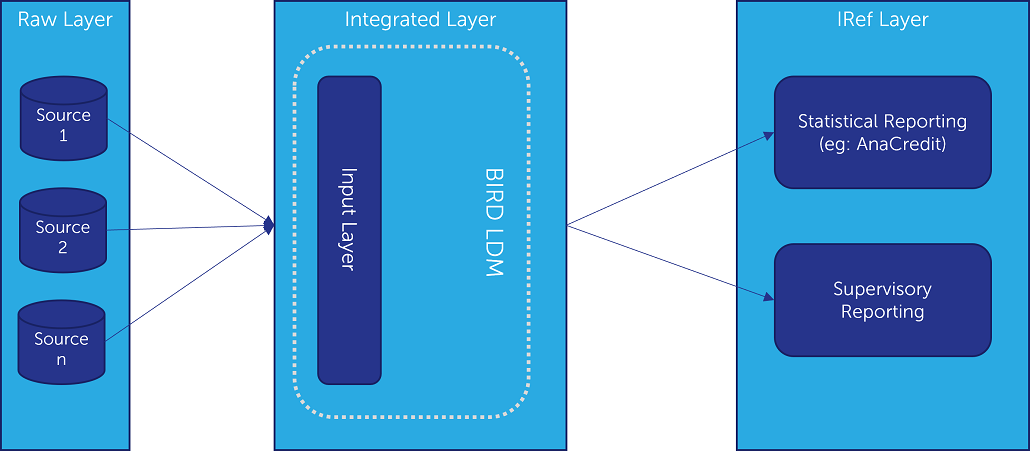
Unlike BIRD, the IRef is expected to be a mandatory regulatory requirement. The ECB is currently in the process of fine tuning and clarifying additional topics relating to IRef (and BIRD). The latest draft regulation is expected in 2024 and it will be subject to a public consultation before it is finalized and adopted. The regulation will then replace the existing legal provisions on the collection of datasets within IRef, and the relevant existing ECB regulations will be repealed or amended, as applicable.
Looking at the features required to solve for BCBS-239 compliance along with the BIRD LDM, it would not be wrong to assume that a lot of the ingredients required for engineering such a solution are already in place. However, building an Integrated Layer that spans across the breadth of the enterprise is not a small undertaking. So why build one?
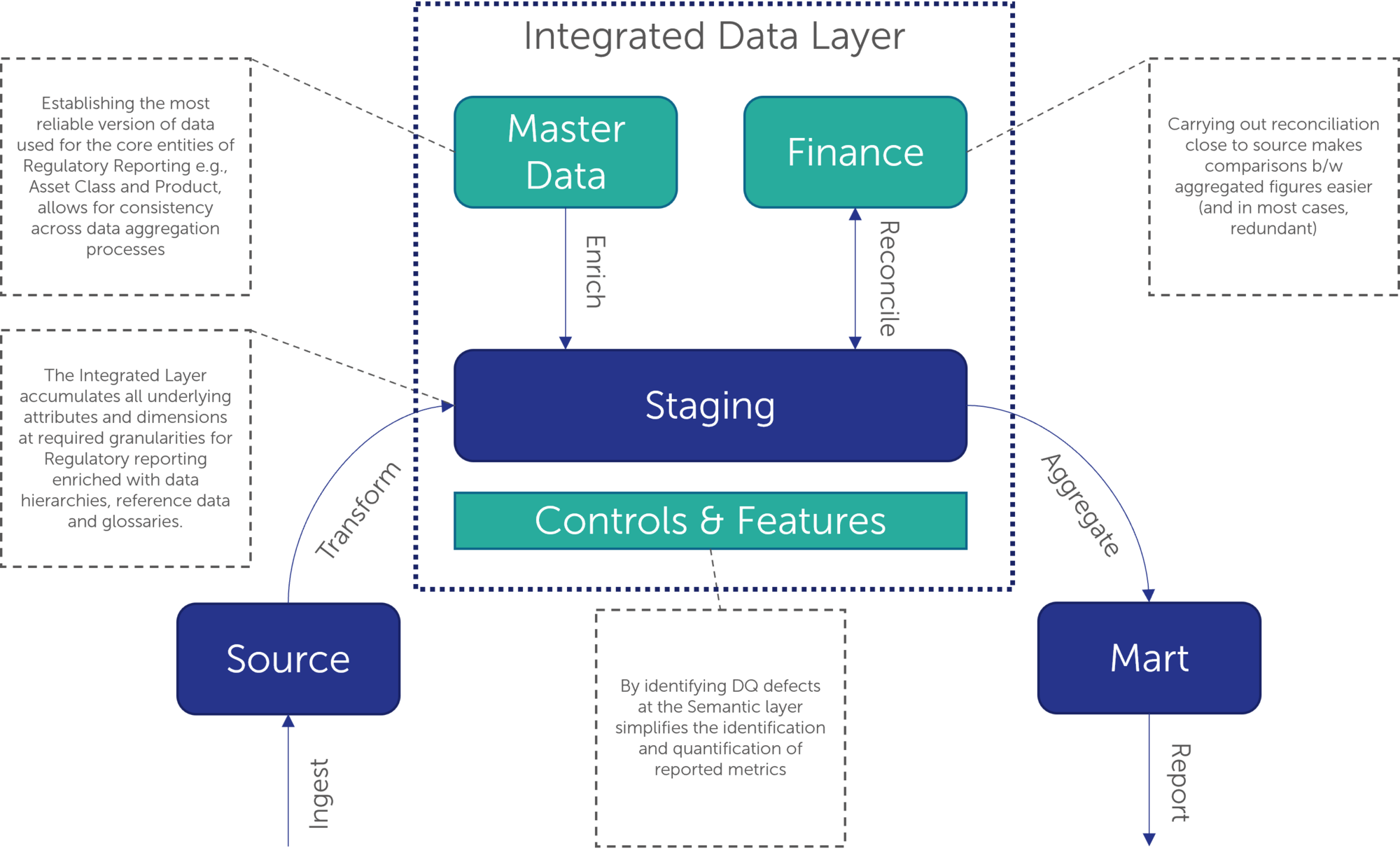
Possibly the most important benefit of creating an Integrated Data Layer is the de-duplication of various transformation, validation and/or aggregation steps. Let us say for example an organisation has a dedicated database for capturing and storing Collateral data. In the absence of any shared data layer on top of this raw database, the same data attributes from this Collateral database would be queried for modelling Loss Given Default (LGD), reporting Loan to Value ratios across products and numerous other processes. In order to maintain compliance, each of these processes would have to define and document business transformation and validation rules, and perform reconciliations to source independently. This is a typical example of technical debt that is accumulated across a data management solution’s lifetime, which eventually turns the change management process for any new change upstream into a quagmire.
An Integrated Layer addresses this problem by implementing all possible business transformation and validation logic at the source to Integrated Data Layer level, eliminating redundancies and also making change management a one-step process as long as there is consensus amongst downstream consumers.
As the requirements around having adequate controls across the lineage of a metric have become more stringent, merely performing additional controls at every data transfer and/or transformation step may not have the intended benefit of improving the accuracy and integrity of the underlying data.
Again, using Collateral as an example, let us say there are two separate processes – the first one intends to use Collateral Value from the underlying database to calculate the Loan to Value of a portfolio. The second process queries the same attribute, albeit independently, but to calculate the Foundation LGD as per the Basel IV requirements. In cases where the collateral values are stale (older than the date of sanctioning of the loan), they can be flagged easily by the first process, by simply having a validation rule that compares the date of sanctioning of the loan with the date of the last valuation capture. However, this might be missed by the second process, as it would not need to fetch the underlying attribute for the loan commencement date in the first place to calculate the Foundation LGD.
Indeed, an Integrated Layer also allows for collating the validation rules and various other controls that have been applied to the same attribute by different processes, to create a more holistic view of data quality and highlight defects for all downstream consumers.
Establishing the most reliable version of data used for the core entities of regulatory reporting e.g., Asset Class, Product, etc. allows for consistency across the enterprise data aggregation process. Practically, how one business unit or a portfolio defines an attribute is understood in the same way across the board.
Although building an Integrated Data Layer is not a requirement for BCBS-239 compliance or a mandate by ECB’s BIRD, banks have a unique opportunity to leverage the work that they are currently undertaking in this space as a starting step to build a strategic data warehouse that can cope with the increasingly granular reporting requirements from regulators in a manner that is true to the spirit of the BCBS-239 regulation. BIRD is nevertheless an additional incentive to adopt this best practice, putting additional pressure on the banks choosing to maintain silos of data while having difficulties to justify inconsistencies across reporting streams.
Bringing in depth regulatory reporting understanding to the data world, Finalyse is best positioned to help banks leveraging the most from the data quality improvements and process efficiency gain while engaging in such a journey. Do not hesitate to ask for a free workshop to know more and analyse how building an Integrated Data Layer could solve your particular challenges.
Finalyse InsuranceFinalyse offers specialized consulting for insurance and pension sectors, focusing on risk management, actuarial modeling, and regulatory compliance. Their services include Solvency II support, IFRS 17 implementation, and climate risk assessments, ensuring robust frameworks and regulatory alignment for institutions. |

Check out Finalyse Insurance services list that could help your business.
Get to know the people behind our services, feel free to ask them any questions.
Read Finalyse client cases regarding our insurance service offer.
Read Finalyse blog articles regarding our insurance service offer.
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department.
Designed to provide cost-efficient and independent assurance to insurance and reinsurance undertakings
Finalyse BankingFinalyse leverages 35+ years of banking expertise to guide you through regulatory challenges with tailored risk solutions. |

Designed to help your Risk Management (Validation/AI Team) department in complying with EU AI Act regulatory requirements
A tool for banks to validate the implementation of RWA calculations and be better prepared for CRR3 in 2025
In 2027, FRTB will become the European norm for Pillar I market risk. Enhanced reporting requirements will also kick in at the start of the year. Are you on track?
Finalyse ValuationValuing complex products is both costly and demanding, requiring quality data, advanced models, and expert support. Finalyse Valuation Services are tailored to client needs, ensuring transparency and ongoing collaboration. Our experts analyse and reconcile counterparty prices to explain and document any differences. |

Helping clients to reconcile price disputes
Save time reviewing the reports instead of producing them yourself
Helping institutions to cope with reporting-related requirements
Be confident about your derivative values with holistic market data at hand
Finalyse PublicationsDiscover Finalyse writings, written for you by our experienced consultants, read whitepapers, our RegBrief and blog articles to stay ahead of the trends in the Banking, Insurance and Managed Services world |

Finalyse’s take on risk-mitigation techniques and the regulatory requirements that they address
A regularly updated catalogue of key financial policy changes, focusing on risk management, reporting, governance, accounting, and trading
Read Finalyse whitepapers and research materials on trending subjects
About FinalyseOur aim is to support our clients incorporating changes and innovations in valuation, risk and compliance. We share the ambition to contribute to a sustainable and resilient financial system. Facing these extraordinary challenges is what drives us every day. |

Finalyse CareersUnlock your potential with Finalyse: as risk management pioneers with over 35 years of experience, we provide advisory services and empower clients in making informed decisions. Our mission is to support them in adapting to changes and innovations, contributing to a sustainable and resilient financial system. |

Get to know our diverse and multicultural teams, committed to bring new ideas
We combine growing fintech expertise, ownership, and a passion for tailored solutions to make a real impact
Discover our three business lines and the expert teams delivering smart, reliable support