

Written by Thomas Gillet, Partner Embex,
and Kristian Lajkep, Regulatory Compliance Officer
On January 2013, the Basel Committee on Banking Supervision has issued a set of principles, so-called BCBS 239, for banks to comply with in terms of their Governance, IT infrastructure, Data aggregation capabilities and Risk reporting practices.
In this paper, whose summary you can find here, the Basel Committee has introduced qualitative expectations for risk reporting organisation, processes and tools and quantitative expectations for reporting. These requirements display an increased focus on data quality, as well as emphasis on risk aggregation, timeliness, accuracy, comprehensiveness and granularity when producing a report. It should be quite clear that following these principles duly is an undertaking that requires tremendous technical and technological sophistication as regards tools, IT infrastructure and computational power. These are apparently difficult to obtain, but not to most financial institutions. The key problem, as we observe, is going about using those tools for a BCBS 239 project.
Most of our clients have launched complex initiatives to set up framework ensuring long-term adhesion to the BCBS 239 Principles, by embedding them into their daily behaviour and risk data and reporting-related practices.
Undertaking such project requires solid experience in managing projects which include several entities (in case the bank is part of a larger group), departments and stakeholders. Indeed, the main apparent challenge of these type of projects is that they are essentially transversal between a number of departments (Risk, Finance & IT). To cope with this, some banks have put in place a so-called Data Office, which takes charge of all data management & data governance initiatives across the bank.
To drive and support BCBS 239 projects, an adequate project management approach enabling a smooth and structured implementation is paramount. It is also crucial to ensure good communication between all the stakeholders and the BCBS 239 project team (whether or not the team is located within the data office department).
Most of enterprises would wish to start their BCBS 239 with the creation of a unified Risk & Finance data warehouse which consolidates and centralised data from different source systems in order to create a reliable single source of information (Data Hub). And here already comes the first stumbling block which needs to be avoided. Building a Risk & Finance Data Hub takes years. We have seen many projects that were in jeopardy or even came to a screeching halt because of lack of concrete delivery (no or little added value for Risk – usually sponsor of the project). Therefore, opting for a piecemeal and iterative, rather than enterprise-wide implementation is crucial, not least in order to be able to answer a not at all unreasonable question of all stake holders: “What are we really getting out of this?”
Although a multitude of different risk reports exists, they all are made with either of two purposes: they are either for risk managers, giving them insight on what is going on within the business – In which case cherry picking the most important information is essential, or they are for regulators or other stake-holders, in which case completeness and compliance with existing rules/standards are the main concern. An iteration consists of rolling out the entire cycle for a subset of reports.
Consequently, Finalyse proposes a top-down approach (starting with the analysis of the reports) that clearly highlights the dependencies between Risk, IT and the Data Offices during the project lifecycle, through a list of clearly identified deliverables that should be produced for each iteration.
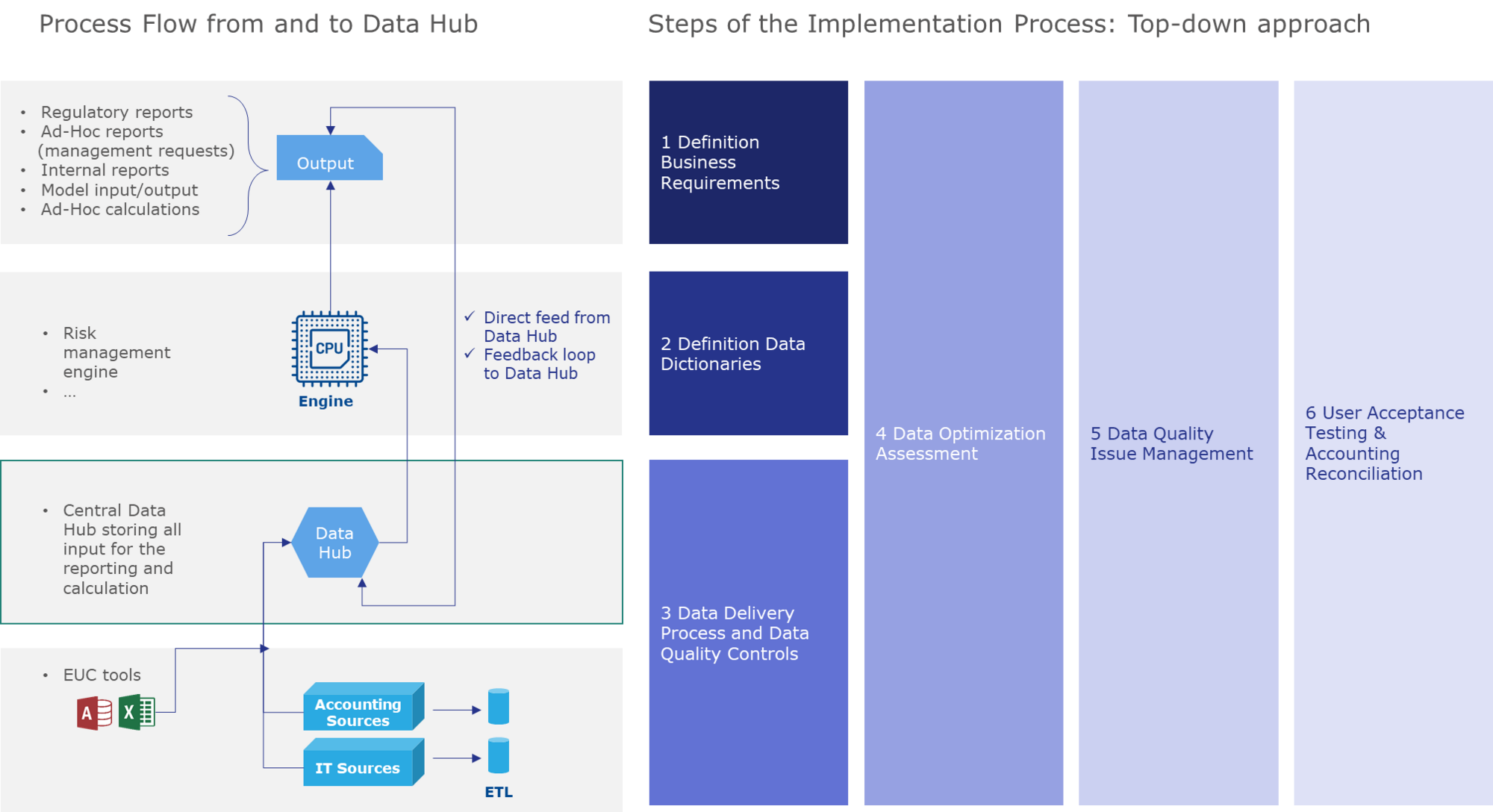
We understand that the scheme above, whilst complete and not complicated, requires some explanation. This section details the respective steps that need to be taken for each iteration.
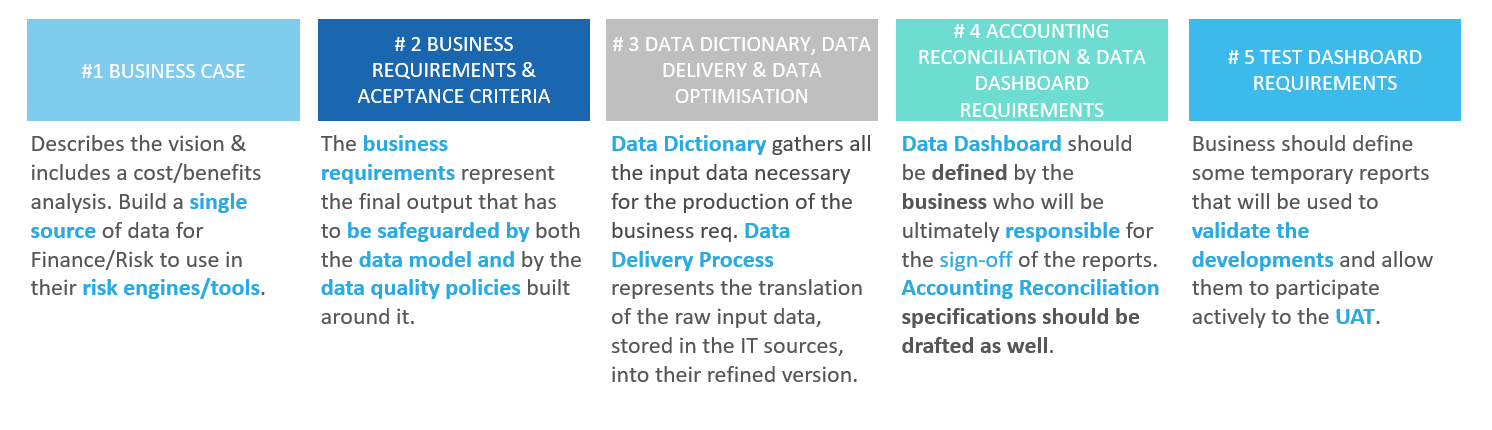
Definition of the business requirements:
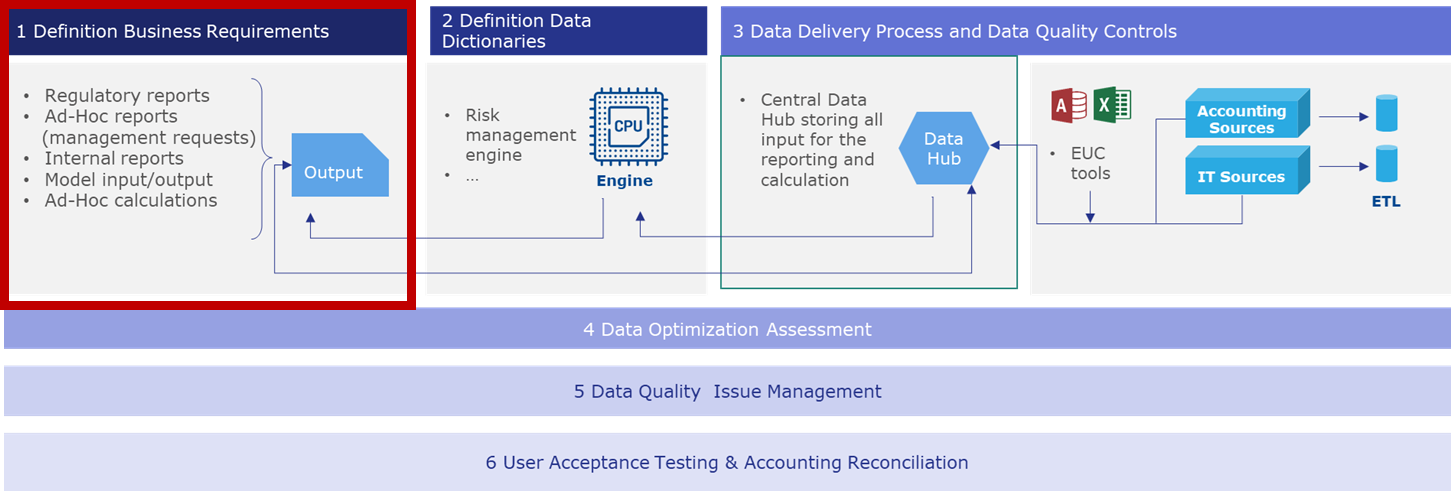
The Business requirements are the final needs of the business users to perform their tasks. These requirements are not limited to a set of data, they are the comprehensive set of all the information on the final outcomes of all the previous reporting or calculations, e.g.:
The business requirements also represent the ambition level from a business perspective:
Definition of the Data Dictionaries
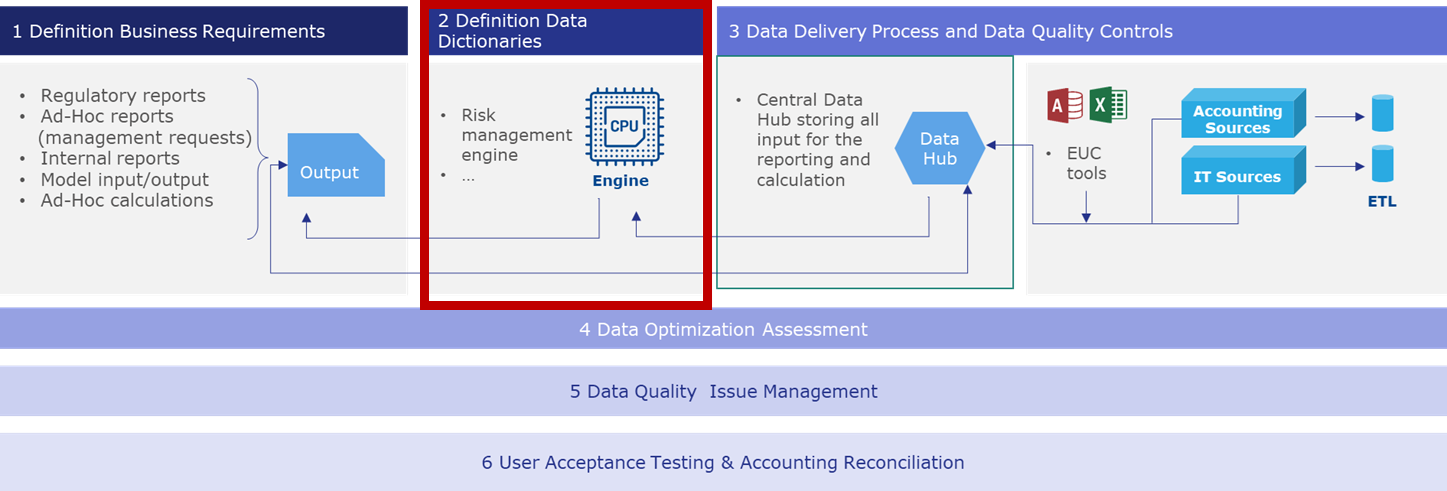
The Data Dictionary is a set of files gathering all the input data necessary for the production of the business requirements following a specific layout:
The Data Dictionaries are the baseline for the creation of the Data Model. They provide a clear view on data via definition and thus are a great way to clean-up the redundant data. The document serves as an exhaustive list of the required data. When an issue arises on data, the user can directly escalate the problem to the responsible department.
Definition of the Data Delivery documentation
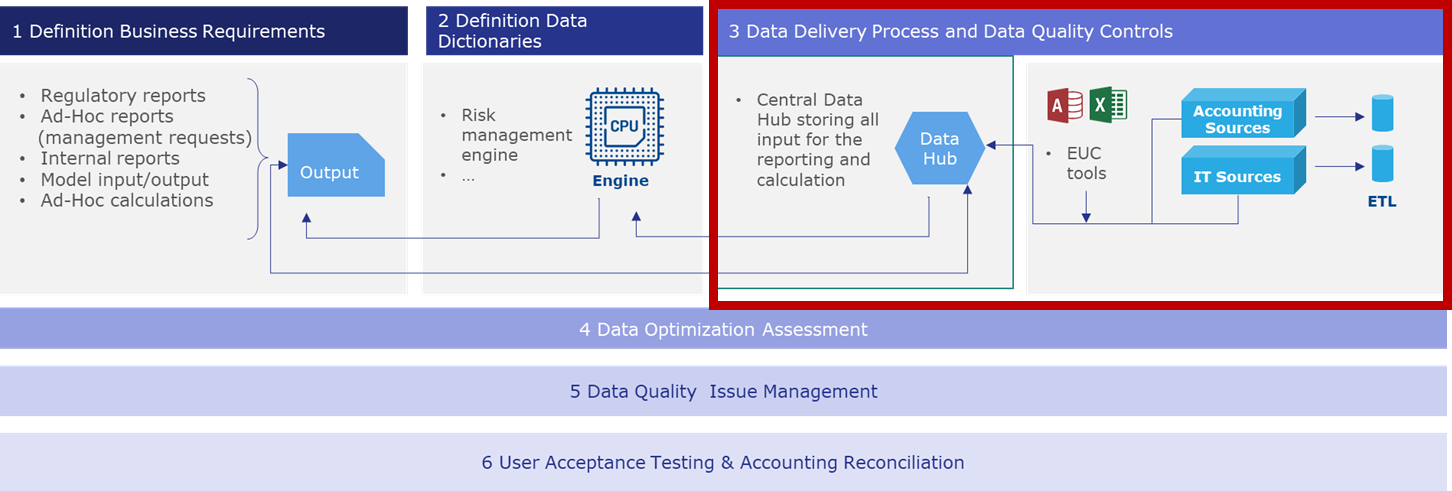
The Data Delivery Process represents the translation of the raw input data, stored in the IT sources, into their refined version translated into the Data Hub. This document provides a high-level overview of the process flow, identifying the main IT sources, players, and data flows from the back-end applications to Data Hub.
In the dataflow between two sources there might also be:
The Data Mappings must define the relationship between the attributes in the source applications and their translation into the Data Hub. The idea of the Data Mapping is to be able to follow every single attribute from the Data Hub back to its original source.
Data Dashboard
The Data Dashboard provides on overview of the quality of the data stored in the Data Hub at an aggregated level. The requirements for the Dashboard should be defined by the business who will be ultimately responsible for the sign-off of the reports produced based on the Data Hub.
Quality of the official report
The final Data Quality overview should be at report level. This overview will provide an overall judgement of the inner quality of the data and maturity of the report, within the DQ framework in place.
Data Optimization Assessment as a complete valuation of the underlying processes
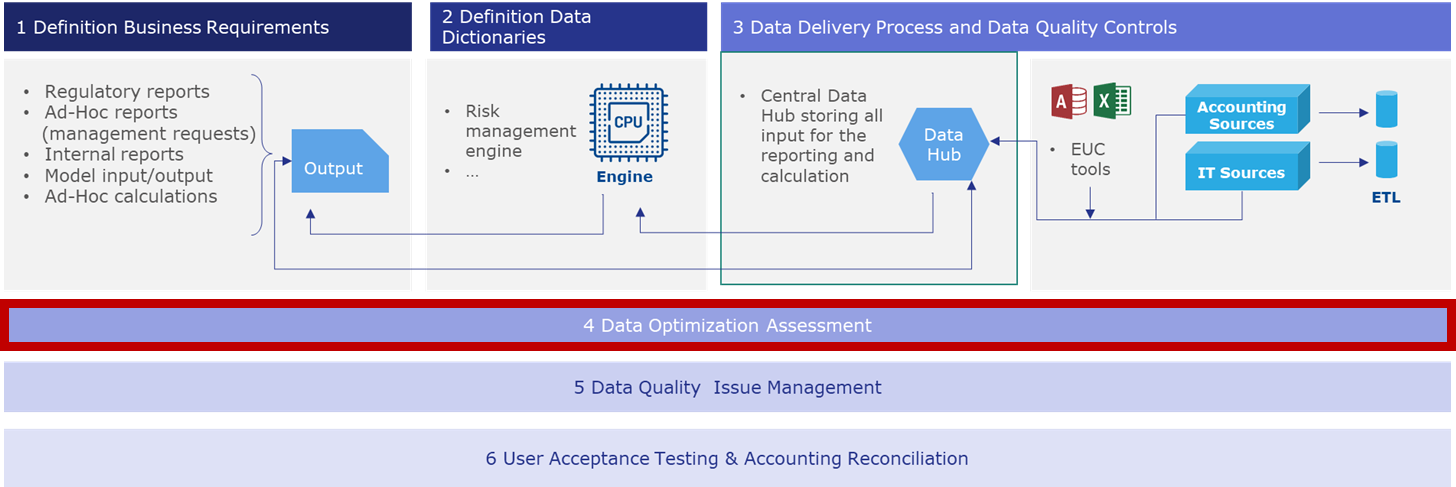
The business and IT personnel should assess the opportunity to optimize some of the underlying processes. Their assessment would contribute to an updated version of the Data Delivery. The Data Optimization typically consists of a file that sets, by schemes and descriptions, the content of the data workflows optimized for each department and for a specific business event.
Data Quality Issue Management
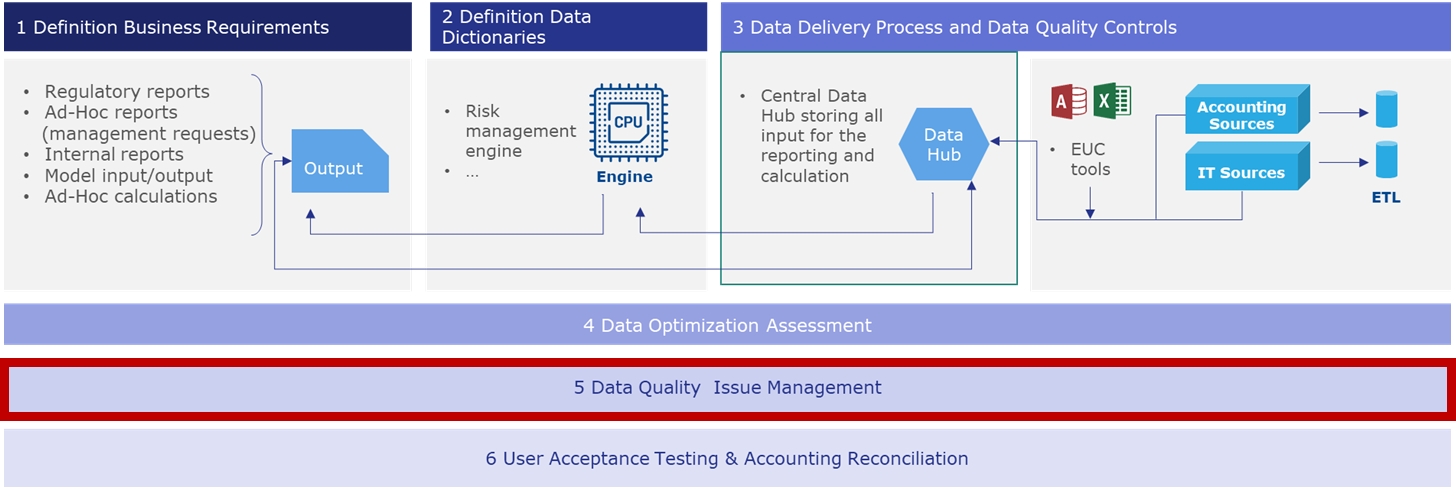
The Data Quality Issue Management is a continuous process involving different responsible persons from the departments involved in the entire process to identify and resolve the data quality issues.
User Acceptance Testing and Accounting Reconciliation
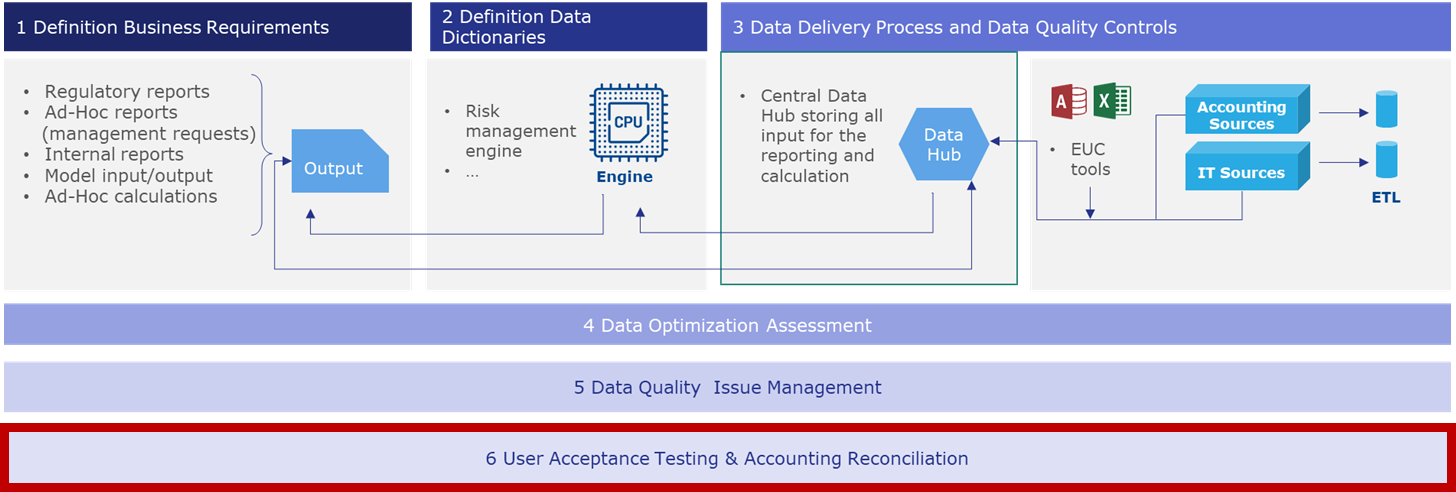
The user acceptance testing activities should be performed only during the testing phase of the implementation and discarded once validated the shift towards Data Hub.
Together with the Data Analyst, the business should help to create a set of unique and consistent metrics representing the quality of the data in Data Hub against the one in the reference dataset.
Once defined, the actors should define for each metric a threshold. When the data are loaded in Data Hub there might be two scenarios:
Once those metrics are satisfactory, the business can perform the core activity of UAT by comparing the newly created output against the ones produced with the reference dataset. Either:
The last step is the reconciliation of the Data Hub output with the Accounting figures
Everything described above refers to the formation of a plan – process routes, descriptions etc. Next step is implementing these plans within the company tools, processes, metrics, and roles/bodies.
Based on our past experience on similar projects, we consider the tight involvement of business to be paramount to the success of the project and expect that at least the following items are delivered by the business representatives (Risk and/or Finance department) to ensure a smooth and viable collaboration with Data Office and the IT teams which are in charge of the development. It is crucial that these are indeed delivered by the business and not outsourced.
The Data Quality Operating Model, switching the gears to the qualitive aspect, is usually organized into four core components that cover people, processes, data, and technology to enable a consistent understanding and implementation of Data Quality capabilities. The Data Hub that is embedded in a broader solution that tackles not only the need in terms of data gathering and data storage but also Metadata, Data Lineage, Data Quality & Data Distribution.
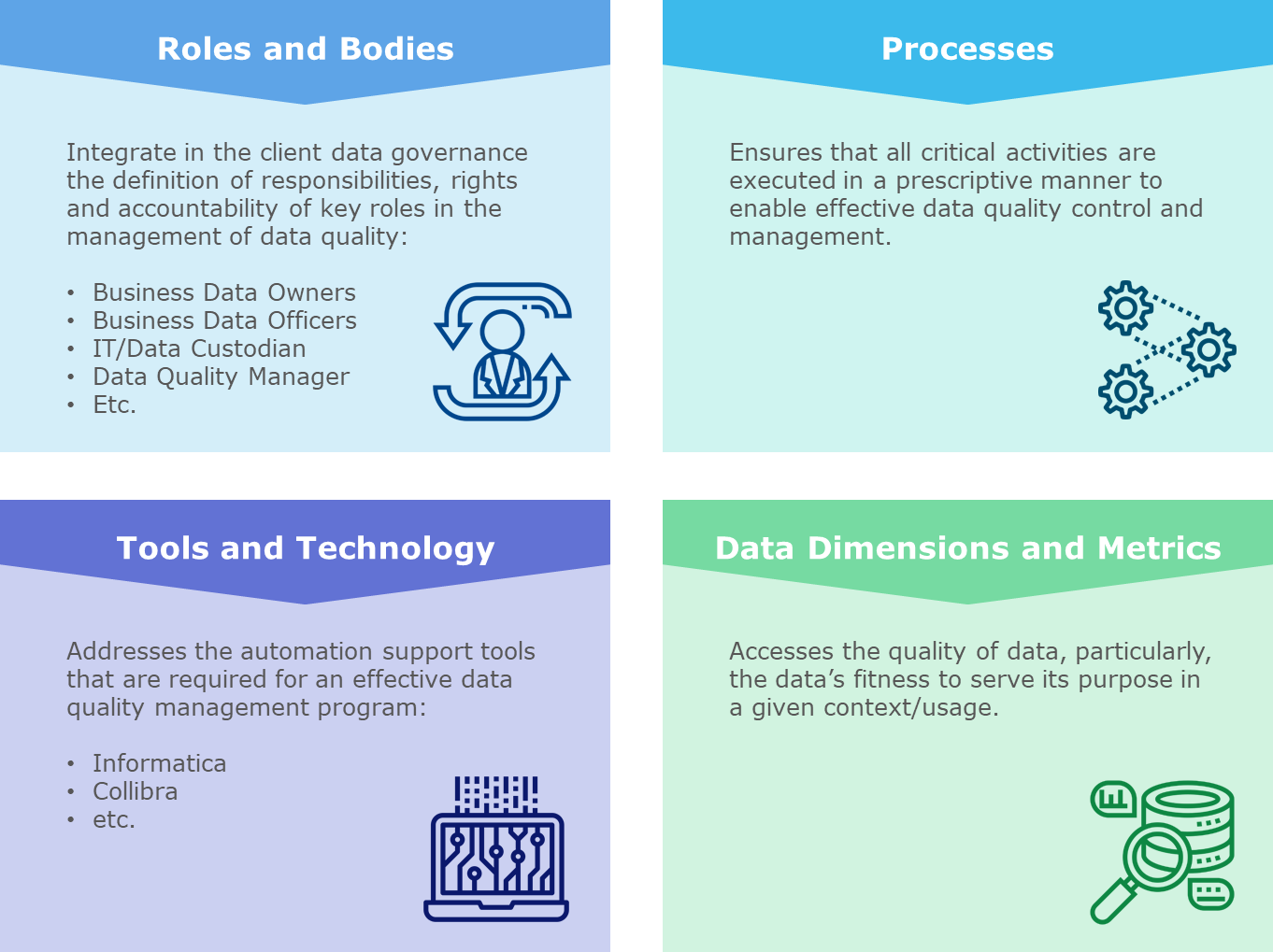
On past projects we observed several pitfalls to avoid, best practices to be put in place and questions to be answered as follows:
It has been noted by our experts that implementing BCBS 239, more so than some other projects, does not require a particularly high level of technical brilliance or sophisticated modelling. However, that does not mean, that the BCBS 239 projects are easy or do not require any sophisticated tools. It is just that the people and plans prove to be much bigger obstacles then the tools. First there is an overall vision – a “big bang” implementation will see the institution run out of patience and a good will well before the project is close to bearing any fruit. An iterative approach is essential. Secondly, when conducting the project, all the departments concerned (and there is a good number of them) must be clear on when they are expected to participate in and how. Typically, a vague instruction mean that most people ignore the necessary actions, with hopes and (often quire sincere) expectations, that somebody else will provide them. On the side of our consultants, getting all of our clients’ departments to seamlessly cooperate and follow one vision may be the most difficult part of this type of project.
Thus, rather than technical skill such projects require a giant portion of common sense coupled with a heathy dose of experience and an ability to manage expectations and to communicate. Both on the side of us as consultants and on the side of our clients.
Finalyse InsuranceFinalyse offers specialized consulting for insurance and pension sectors, focusing on risk management, actuarial modeling, and regulatory compliance. Their services include Solvency II support, IFRS 17 implementation, and climate risk assessments, ensuring robust frameworks and regulatory alignment for institutions. |

Check out Finalyse Insurance services list that could help your business.
Get to know the people behind our services, feel free to ask them any questions.
Read Finalyse client cases regarding our insurance service offer.
Read Finalyse blog articles regarding our insurance service offer.
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department.
Designed to provide cost-efficient and independent assurance to insurance and reinsurance undertakings
Finalyse BankingFinalyse leverages 35+ years of banking expertise to guide you through regulatory challenges with tailored risk solutions. |

Designed to help your Risk Management (Validation/AI Team) department in complying with EU AI Act regulatory requirements
A tool for banks to validate the implementation of RWA calculations and be better prepared for CRR3 in 2025
In 2027, FRTB will become the European norm for Pillar I market risk. Enhanced reporting requirements will also kick in at the start of the year. Are you on track?
Finalyse ValuationValuing complex products is both costly and demanding, requiring quality data, advanced models, and expert support. Finalyse Valuation Services are tailored to client needs, ensuring transparency and ongoing collaboration. Our experts analyse and reconcile counterparty prices to explain and document any differences. |

Helping clients to reconcile price disputes
Save time reviewing the reports instead of producing them yourself
Helping institutions to cope with reporting-related requirements
Be confident about your derivative values with holistic market data at hand
Finalyse PublicationsDiscover Finalyse writings, written for you by our experienced consultants, read whitepapers, our RegBrief and blog articles to stay ahead of the trends in the Banking, Insurance and Managed Services world |

Finalyse’s take on risk-mitigation techniques and the regulatory requirements that they address
A regularly updated catalogue of key financial policy changes, focusing on risk management, reporting, governance, accounting, and trading
Read Finalyse whitepapers and research materials on trending subjects
About FinalyseOur aim is to support our clients incorporating changes and innovations in valuation, risk and compliance. We share the ambition to contribute to a sustainable and resilient financial system. Facing these extraordinary challenges is what drives us every day. |

Finalyse CareersUnlock your potential with Finalyse: as risk management pioneers with over 35 years of experience, we provide advisory services and empower clients in making informed decisions. Our mission is to support them in adapting to changes and innovations, contributing to a sustainable and resilient financial system. |

Get to know our diverse and multicultural teams, committed to bring new ideas
We combine growing fintech expertise, ownership, and a passion for tailored solutions to make a real impact
Discover our three business lines and the expert teams delivering smart, reliable support