Written by Bartłomiej Polaczyk, Senior Consultant, reviewed by Maciej Jarosiński, Senior Consultant.

Maciej is a Managing Consultant with 7 years of experience in model development and validation, specialising in machine learning and regulatory credit risk. He has hands-on expertise in building and assessing ML models for applications such as customer segmentation and credit scoring, including the use of alternative data sources as well as Pillar 1 and Pillar 2 modelling experience which he gained on projects completed for clients across Europe and the Middle East.
In this post, we present a comprehensive summary and commentary of (Halperin, 2020). We address one of the issues of the Black-Scholes model, which is the premise that a perfect hedge is possible, which is not true in the real world. One of the reasons behind this inefficacy is the assumption of continuous portfolio rebalancing. We present a discrete setup of the model and show how to solve it with reinforcement learning techniques.
In this post, we
Particularly, we obtain a reinforcement learning algorithm that can solve the discrete BS model optimization problem. Its solution provides both an optimal hedge and an option price simultaneously. This is precisely the QLBS model introduced by Halperin.
Let Bt be a risk-free bank deposit and St be a stock value. We assume that there is a risk-free rate r and that St follows the log-normal distribution with some fixed volatility σ and drift μ , i.e.,
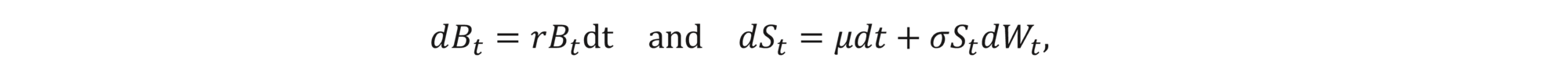
where Wt is the Wiener process. We consider a European option with a payoff H(ST) for some termination date T. Finally, we denote by Vt=V(S,t) the value of the option at time t .
Our aim is to construct a hedge portfolio for this option. We denote the portfolio value at time t by Πt . We assume that the portfolio consists only of stock shares and money and that it covers the payoff at the termination, i.e.,

where ut and xt are the amounts of shares and money held in the portfolio at time t according to the specified strategy. The crucial assumption we make is that the portfolio is self-financing, which means that the change in its value comes only from the change in the value of instruments held. Mathematically, this can be expressed as
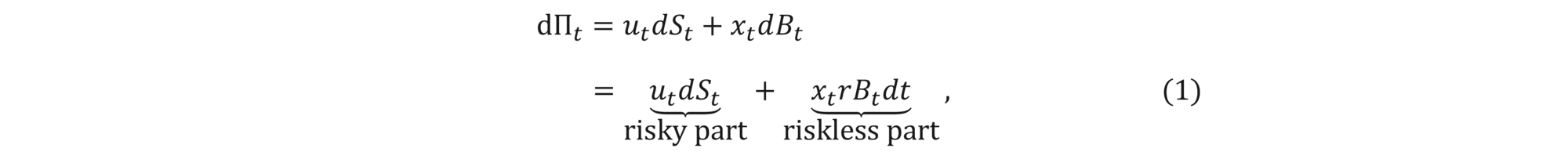
cf. this post for an intuitive explanation of the formula. We want to determine how much money and stock to keep in the portfolio at each time to cover the option price. In our model, the option price Vt depends only on the current stock price and current moment in time, i.e., Vt=V(St,t). We therefore use Itô's lemma and obtain that
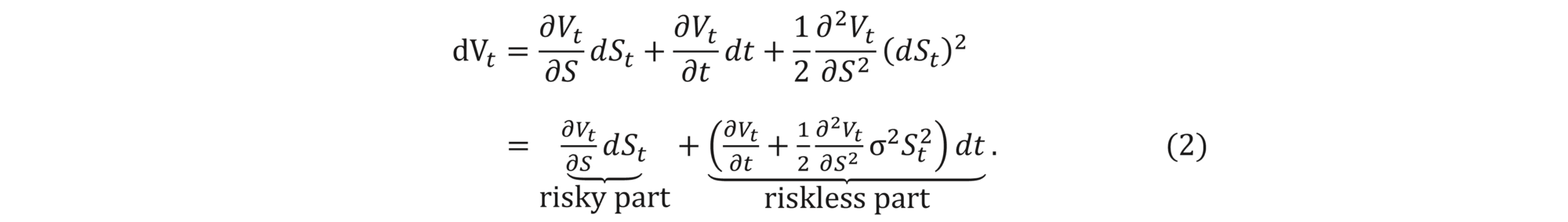
Equating the risky and riskless parts of equations (1) and (2) shows that a perfect hedge is possible for
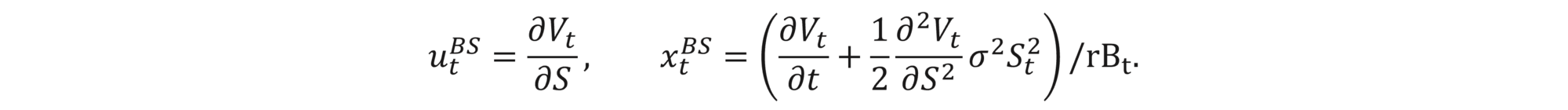
This is the proclaimed delta-hedge strategy. The name comes from the fact that ∂Vt / ∂S is precisely the delta of the option. Since VT=H(ST)=ΠTBS and since Vt and ΠtBS have the same dynamics under this strategy, we obtain that Vt=ΠtBS at each time, which means that we have a perfect hedge. The relation Vt=ΠtBS is therefore the renowned Black-Scholes equation,
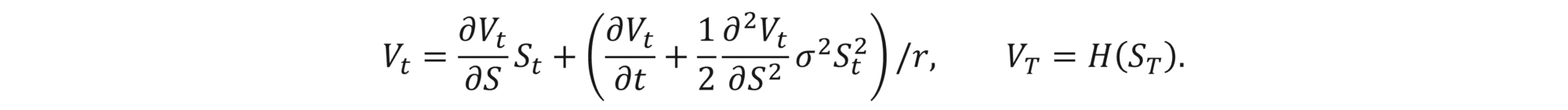
The result above suggests something paradoxical – if an option can be perfectly hedged with a simple portfolio consisting of stock and cash, then trading options makes no sense and options are completely redundant. The reason why this is simply not true is that options are not risk-free. There are multiple risk sources in option trading, including, e.g., volatility risk, spread risk, transaction costs, etc. Below, we focus on the mis-hedging risk, which arises when we remove the assumption that the portfolio can be continuously rebalanced.
We assume that we can only observe the world in between discrete time-step intervals Δt (corresponding to the rebalancing frequency assumed by the trader). This results in the following bank account dynamics:
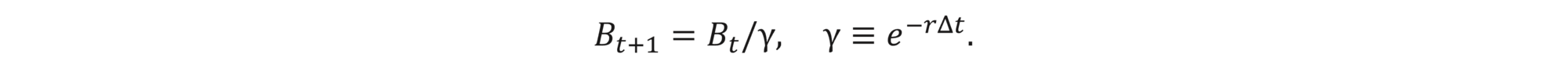
We again consider a self-financing hedge portfolio Πt with the terminal condition ΠT= H(ST). Remember that the self-financing condition says that any change in the portfolio value comes from the change of the value of the instruments held. In our setting,
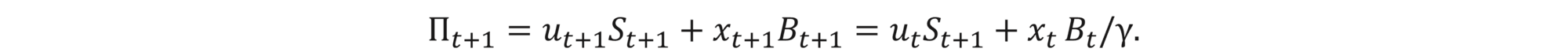
This relation allows to express xt in terms of ut, St+1, Bt/γ and Πt+1 , thus henceforth we will disregard xt and associate the strategy (ut,xt) with (ut) only. Additionally, we have the following recursive relation:
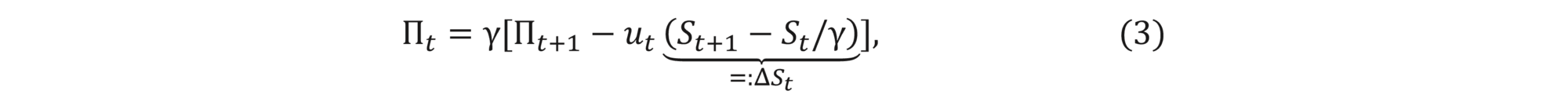
which will be useful later.
From a trader’s perspective, for a given hedge strategy (ut), the option ask price at time t, Ct, is the average hedge cost, Vt=E[Πt | St], plus some risk premium. Mathematically speaking, this can be expressed in the following way:
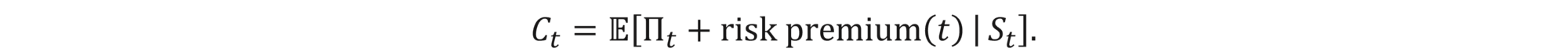
While in the BS world, the risk premium is zero due to the existence of the perfect hedge, in the discrete world, the premium is proportional to the risk taken. Therefore, a natural choice of the optimal hedge strategy, when minimizing risk, is the one that minimizes the uncertainty at each step, i.e.,
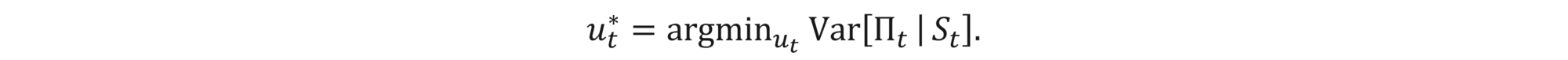
Using only the recursive relation (3), the optimal solution can be found analytically to be
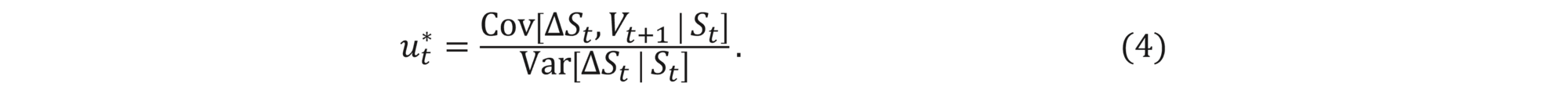
Assuming log-normal distribution of the underlying and taking the limit Δt →0 retrieves the delta-hedge strategy described in the previous section, i.e.,
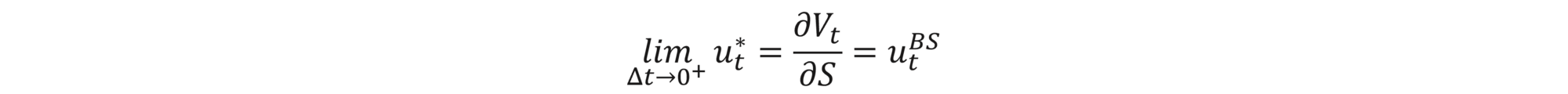
as well as the BS equation (we omit technical details here). Therefore, this discrete model is a generalization of the continuous one and an important step towards removing the BS inefficacies. In the following sections, we will explain how to solve it numerically and how to view it from the Q-learning perspective.
We have made a step towards generalizing the Black Scholes model. With our current setup, we can find the option ask price Ct and an optimal strategy using the standard backward algorithm (this requires assuming the underling dynamics and the risk premium formula). In the following sections, we introduce a reinforcement learning algorithm and then extend the above formulation even further to the form that can be solved with the use of the algorithm. As a result, we will obtain a method for calculating both hedge and price simultaneously without any underlying dynamics assumptions.
Let us take a small detour and talk about Q-learning which is a reinforcement learning (RL) algorithm.
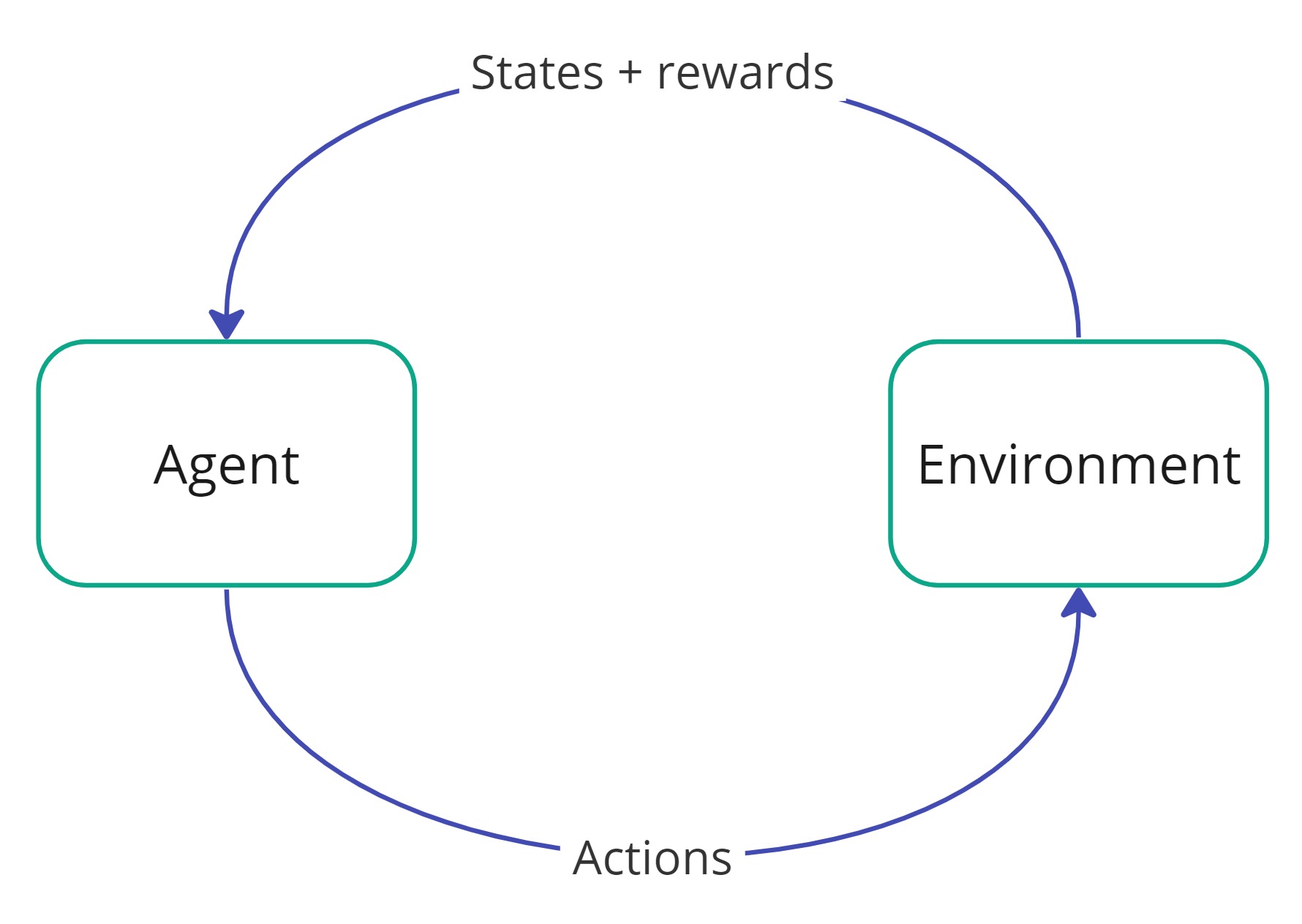
The basic setup of RL is that we have an agent and an environment. The agent observes a state of the environment, based on which they take an action, which results in a new state, based on which a new action is taken, etc. until some terminal condition occurs. Additionally, each state-action pair is associated with some reward returned by the environment, which tells how preferable being in the corresponding state and performing the action is.
The main goal of an RL algorithm is to learn a set of rules which tell the agent which action to take depending on the current state. Such set of rules is called a policy. Mathematically, a policy π is just a function that takes arguments in the state space and returns values in the action space, i.e., π(s)=a means that the agent should choose an action a, whenever in a state s. One can also consider random policies (with a random distribution over the action space) but here we restrict our attention to deterministic ones.
How to determine which action to take? As mentioned, moving with an action a from a state s to a state s', results in a reward, which we denote by R(s, a, s'). The total reward related to a policy π is the sum of the discounted future rewards, i.e.,
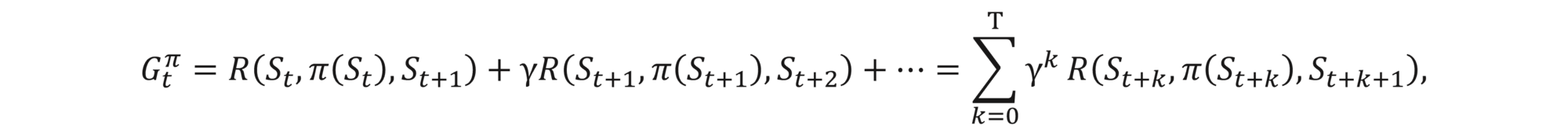
where S0, S1,… are the consecutive state realizations, γ is the discount factor and T is the time horizon (can be infinite). Note that, as the environment can be random, states St are also random and so is Gtπ. An optimal policy π* is the one that maximizes all expected discounted future rewards, i.e.,
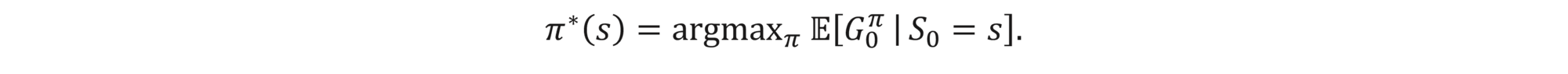
How to find π*? There are various approaches to that problem. One prominent example is the Q-learning algorithm, which we describe below.
A Q-function is a function that tells what the expected future reward is if the agent in a state s chooses an action a first and then follows a policy π. Mathematically,
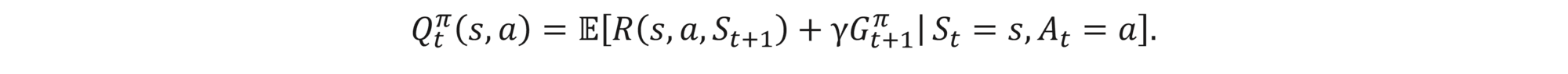
The total reward for the optimal policy is equal to the immediate reward resulting in performing optimal action at the current state and then total reward coming from following the optimal policy, which is mathematically expressed as
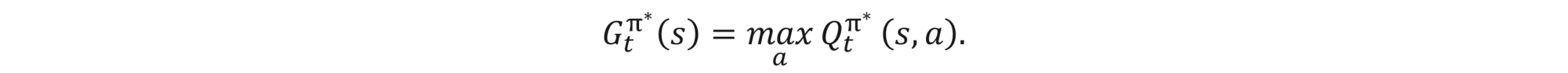
Therefore
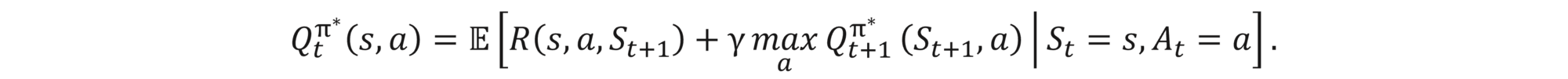
which is called Bellman’s optimality equation.
If we assume that our state process S is Markovian, then Qt becomes independent of t. Q-learning algorithm is a value-iteration algorithm, which can then be described as follows:
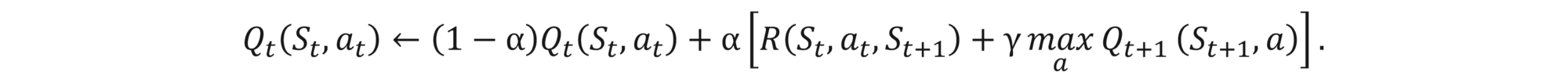
This procedure is guaranteed to converge given enough training data, and results in an optimal Q-function (more precisely, a family (Qt) of Q-functions, if we have a time dependent case). This is a simple version of the algorithm, which has many alternative approaches that fix some of the issues (e.g., it can be accelerated if step 6. is performed batch-wise, or the convergence can be improved if in step 3. we choose at in ε-greedy fashion). For a more detailed view of the RL methods, we recommend this blog.
The optimal policy at time t can then be easily read from Q,

Above, we have silently assumed that the state-action space is finite (in which case given enough training data, the above procedure always converges). This assumption is crucial for the standard Q-learning algorithm and makes Q simply a table of values indexed by (state, action) pairs. There are multiple extensions (e.g., fitted Q-iteration, deep Q-learning), which allow getting rid of this assumption and use a functional approximation to the Q function, but pursuing this direction is beyond the scope of this blog post. Here, we just mention that those difficulties can indeed be overcome.
After the above recap, let us see the problem of the portfolio hedging in the discrete BS model via the lens of Q-learning notation.
In our setting, stock value space is the state space, and actions are associated with the amount of the stock kept in the hedge portfolio, while the policy tells us how much stock to keep, given its value: π(st)=ut. Remember the option ask price formula Ct=E[Πt+risk premium(t) | St] .
Let us try to define the total reward in the model. From the trader’s perspective, being able to hedge the position better (lower risk) results in a lower ask price. Therefore, a trader’s total reward is negatively proportional to the ask price. Ignoring the positive multiplicative factor, we can thus set:

We still need to define the risk premium, which is a component of Ct . (Halperin, 2020) gave the following definition in the spirit of Markovitz portfolio optimization theory:
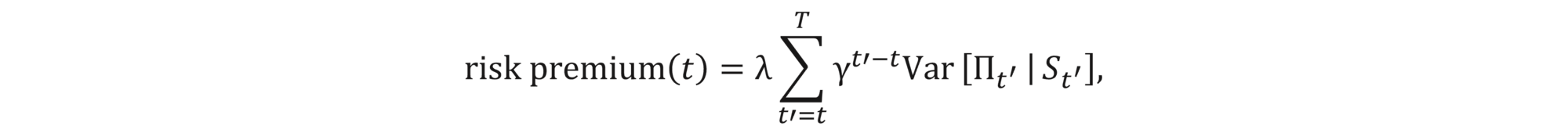
where λ≥0 is the risk aversion parameter. The total reward is then given by
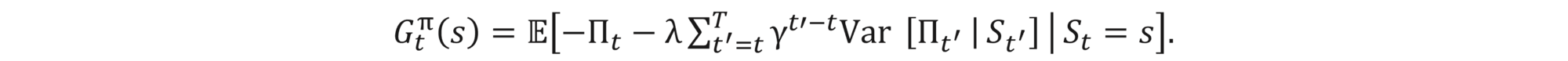
Note that we have not assumed anything about local rewards. We do not even know yet if the total reward can be decomposed into the sum of local rewards as was the case in the previous section. In fact, such decomposition is not required, as for our algorithm to work, we only need to have (some sort of) Bellman’s optimality equation, which we will obtain soon.
For now, we can show the formula for the Q-function. Remember that it is the expected total reward given that we are in a specified state, do a specified action and then follow a specified strategy. Therefore
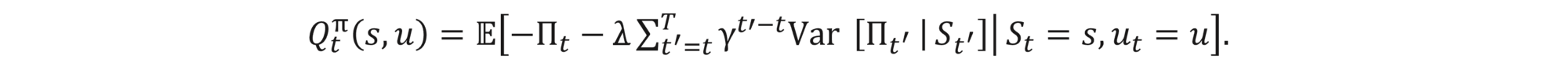
Using only the recursive relation (3), tower rule and defining the one-step reward to be

(Halperin, 2020) proves the following Bellman’s optimality equation
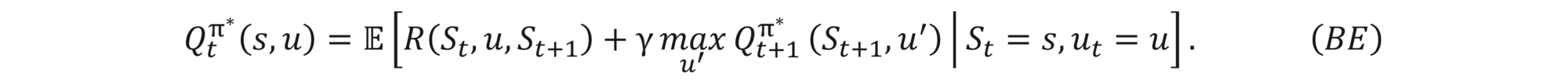
Assuming that we are not policymakers (i.e., the stock value is independent of our actions), we can now use Bellman’s equation to easily solve analytically for the best policy
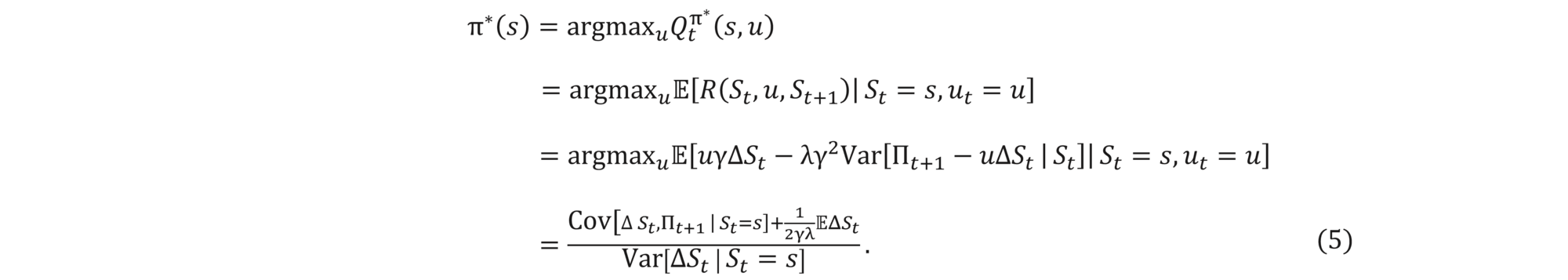
Note that the only difference between (4) and (5) lies in the last parameter EΔSt/2γλ. This is consistent with the fact that in (4) we are only minimizing the risk, while in the total reward Gtπ, we also have a linear term -Πt, which makes the resulting hedges different. In a sense, (5) is a generalization of (4), and (4) can be retrieved from (5) by setting λ= ∞ (i.e., pure risk minimization).
If we have access to transition probabilities (i.e., we make some strong model assumptions), then (5) is already good enough and can be solved by the dynamic programming techniques (in the spirit of American option valuation using Longstaff-Schwarz method).
However, the main observation is that we can go model-free already from Bellman’s optimality equation (BE). Thanks to the fact that we have formulated our problem in the language of RL, we can apply the Q-learning algorithm introduced previously directly to (BE). This has a huge advantage being that we do not need any model assumptions and can train the resulting QLBS algorithm using either synthetic or real data.
The additional advantage of learning the Q-function directly (via the Q-learning) is that having the Q-function, we can read from it both the option price and the optimal hedge strategy at the same time without any need for additional computation. We simply have
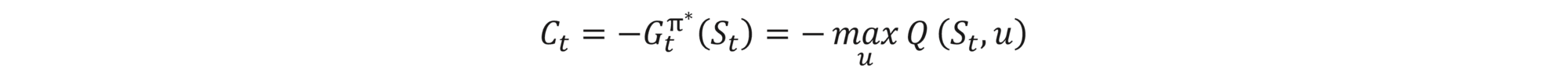
and
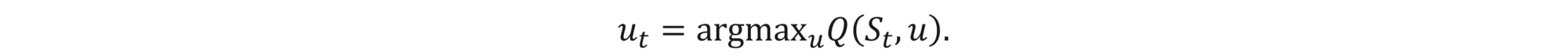
One technical difficulty that must be overcome in the Q-learner approach is that the state space is not discrete by default. This is either circumvent by discretizing the state space or by applying the beforementioned function expansion method of the Q-function (e.g., fitted Q-learning approach). We refer to (Halperin, 2020) for more details.
Let us summarize some main take-away points:
Halperin, I. (2020). QLBS: Q-Learner in the Black-Scholes(-Merton) Worlds. The Journal of Derivatives.
Finalyse InsuranceFinalyse offers specialized consulting for insurance and pension sectors, focusing on risk management, actuarial modeling, and regulatory compliance. Their services include Solvency II support, IFRS 17 implementation, and climate risk assessments, ensuring robust frameworks and regulatory alignment for institutions. |

Check out Finalyse Insurance services list that could help your business.
Get to know the people behind our services, feel free to ask them any questions.
Read Finalyse client cases regarding our insurance service offer.
Read Finalyse blog articles regarding our insurance service offer.
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department
Designed to meet regulatory and strategic requirements of the Actuarial and Risk department.
Designed to provide cost-efficient and independent assurance to insurance and reinsurance undertakings
Finalyse BankingFinalyse leverages 35+ years of banking expertise to guide you through regulatory challenges with tailored risk solutions. |

Designed to help your Risk Management (Validation/AI Team) department in complying with EU AI Act regulatory requirements
A tool for banks to validate the implementation of RWA calculations and be better prepared for CRR3 in 2025
In 2027, FRTB will become the European norm for Pillar I market risk. Enhanced reporting requirements will also kick in at the start of the year. Are you on track?
Finalyse ValuationValuing complex products is both costly and demanding, requiring quality data, advanced models, and expert support. Finalyse Valuation Services are tailored to client needs, ensuring transparency and ongoing collaboration. Our experts analyse and reconcile counterparty prices to explain and document any differences. |

Helping clients to reconcile price disputes
Save time reviewing the reports instead of producing them yourself
Helping institutions to cope with reporting-related requirements
Be confident about your derivative values with holistic market data at hand
Finalyse PublicationsDiscover Finalyse writings, written for you by our experienced consultants, read whitepapers, our RegBrief and blog articles to stay ahead of the trends in the Banking, Insurance and Managed Services world |

Finalyse’s take on risk-mitigation techniques and the regulatory requirements that they address
A regularly updated catalogue of key financial policy changes, focusing on risk management, reporting, governance, accounting, and trading
Read Finalyse whitepapers and research materials on trending subjects
About FinalyseOur aim is to support our clients incorporating changes and innovations in valuation, risk and compliance. We share the ambition to contribute to a sustainable and resilient financial system. Facing these extraordinary challenges is what drives us every day. |

Finalyse CareersUnlock your potential with Finalyse: as risk management pioneers with over 35 years of experience, we provide advisory services and empower clients in making informed decisions. Our mission is to support them in adapting to changes and innovations, contributing to a sustainable and resilient financial system. |

Get to know our diverse and multicultural teams, committed to bring new ideas
We combine growing fintech expertise, ownership, and a passion for tailored solutions to make a real impact
Discover our three business lines and the expert teams delivering smart, reliable support